SpeedReader: Fast and Private Reader Mode for the Web
This post is an abbreviated version of this report, based on research conducted at Brave by Andrius Aucinas (Performance Researcher), Peter Snyder (Privacy Researcher), and Dr. Ben Livshits (Chief Scientist), as well as by Mohammad Ghasemisharif (Ph.D student in Computer Science at the University of Illinois at Chicago and intern at Brave).
Summary: SpeedReader is Brave’s new approach to reader mode, the browser tool that makes web pages more pleasant and less complex to read. By removing all non-essential content before a page loads, SpeedReader goes beyond reader mode’s aesthetic improvements and delivers:
- radical performance gains (speedups ranging from 20× to 27×, bandwidth savings on the order of 84×, and memory reduction of 2.4×);
- significant privacy benefits, which include a complete elimination of ad and tracking related requests.
SpeedReader is useful on 22% of web pages in general, and has even higher applicability for user-shared content (31% on X (formerly Twitter) and 42% on Reddit).
A New Approach to Reader Modes: Performance and Privacy Gains
The modern web’s progress has led far beyond Hypertext Markup for document discovery, with media-rich experiences and dynamic applications. Such growth in capability has however resulted in page “bloat,” making pages expensive to load, and bringing along ubiquitous advertising and tracking.
Web browsers sometimes need to intervene for users to continue enjoying the web. As such, major browsers include a reader mode, which reduces the visual complexity of web sites by eliminating distracting ads, videos, sponsored content links, and other web elements not essential to the page. Reader modes aim to make the reading experience more pleasant, but do not try to improve page load times or protect users’ privacy, as the entire page is loaded first, before removing the bloat.
To address these issues, Brave is developing SpeedReader. SpeedReader is a new approach to reader modes. It delivers huge improvements to not only the aesthetics of the browsing experience, but to browsing performance and privacy as well. For suitable pages, SpeedReader removes all non-essential content before page load, saving time, bandwidth and removing ads and trackers; in that SpeedReader goes beyond what Brave does by default in terms of blocking trackers and ads. SpeedReader automatically detects which pages are suitable, significantly improving the end-user experience – especially on slower mobile connections.
On applicable pages, SpeedReader speeds up page loading by 27×, and reduces network use by 84×, compared to regular browsing. SpeedReader improves user privacy as well, by removing all commonly recognized trackers. During testing, SpeedReader issued 115 fewer requests to third parties, and interacted with 64 fewer trackers on average, on applicable pages. SpeedReader works on 22% of web pages in general, and a full 46% of pages shared on social media.
SpeedReader Strategy
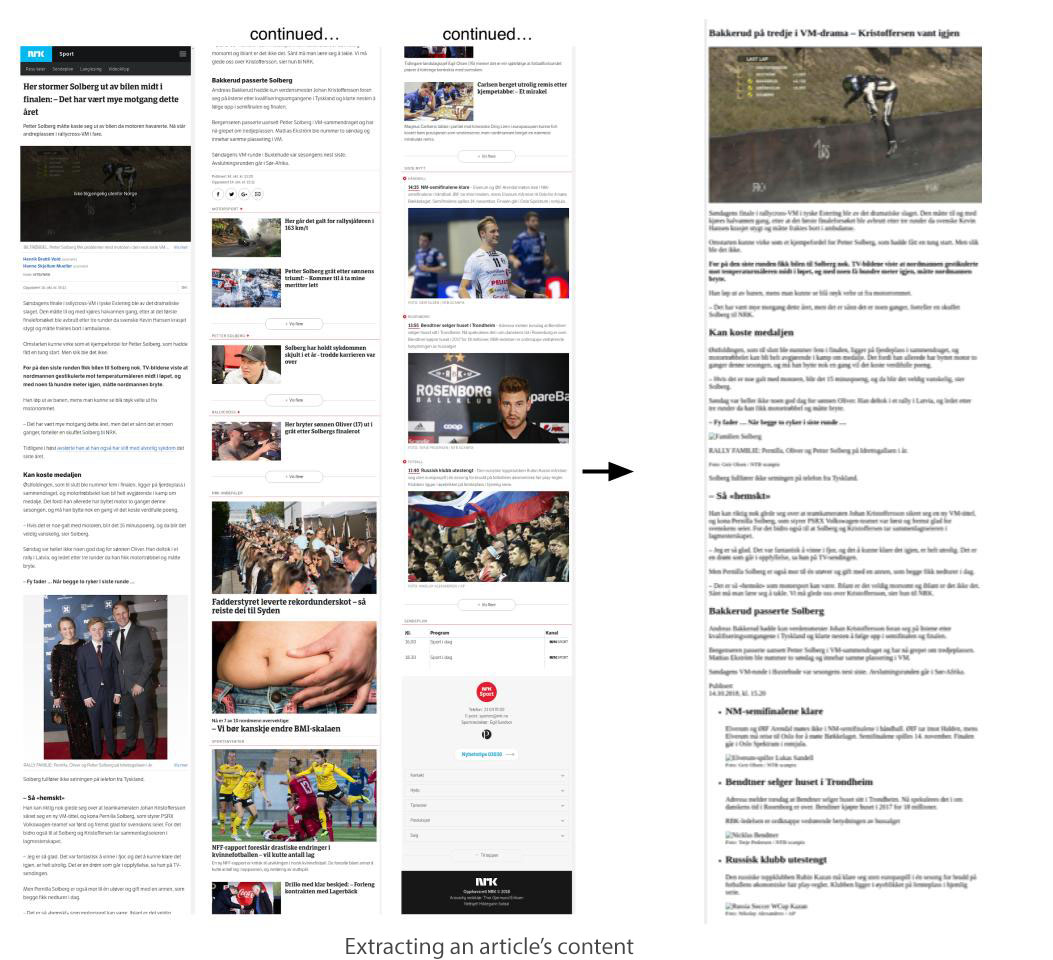
Current reader modes do not save network and memory resources, since reader modes fetch the page’s resources before rendering the “readable” version. Our technique provides a user experience similar to existing reader mode tools, but with network, performance and privacy improvements that exceed existing ad and tracking blocking tools, on a significant portion of websites. The key difference is that SpeedReader operates before page rendering, which allows it to determine which resources are needed for the page’s core content before fetching anything.
SpeedReader achieves performance improvements through a two-step pipeline:
- A Machine Learning classifier to determine whether there is a readable subset of the initial, fetched page HTML. In our tests, it determines whether a page can be displayed in reader mode with 91% accuracy.
- If the classifier has determined that the page is readable, SpeedReader extracts the readable subset of the document before rendering, currently using existing, battle-tested algorithms, and continues rendering the document.
In turn, for documents which SpeedReader determines are readable, the sources of SpeedReader improvements include:
- Never fetching or executing script or CSS.
- Fetching far fewer images or videos (since images and videos not core to the page’s presentation are never retrieved).
- Performing network requests to far fewer third parties (zero, in the common case).
- Saving processing power from not rendering animations, videos or complex layout operations, since reader mode presentations of page content are generally simple.
We trained our classifier on 3,000 pages, considering a page readable if the primary utility of the page was its text and image content, and the usefulness of the page’s content was not dependent on its specific presentation or layout on the website. This meant that single page applications, index pages, and pages with complex layout were generally labeled as not-readable, while pages with static content, a lot of text and content-depicting media were generally labeled readable. In the dataset, our trained classifier was accurate 91% of the time (with 91% precision and 87% recall).
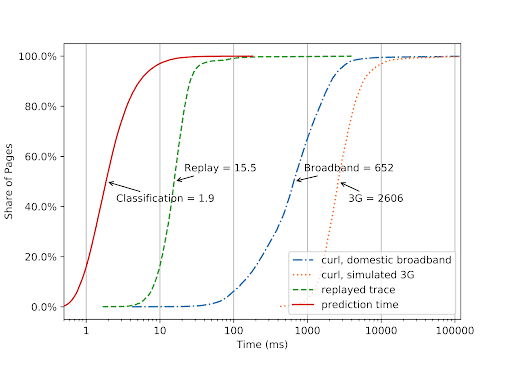
Because the classifier operates on complete HTML documents before they are rendered, the browser is not able to render the document until the entire initial HTML is fetched and classified, requiring it to be fast. We compared classification time to initial HTML download time across more than 90,000 pages from 5,000 popular (Alexa top 5k) and 5,000 less popular (a random sample of Alexa 5k to 100k) pages. We measured the download time under different network conditions, including a fast domestic broadband connection (50 Mbps symmetric bandwidth and 2 ms latency) and emulated 3G using MacOS Network Link Conditioner, using the default 3G preset with 780 kbps downlink, 330 kbps uplink, 100 ms packet delay in either direction and no additional packet loss. For comparison, we also included the time taken to download the same document in Brave, replayed from a local server.
The result is clear at a glance – in the median case, classification took just 1.9 ms, while an initial HTML document load took 652ms on a broadband connection and as much as 2.6 seconds on 3G – that is before downloading any other resources generally needed to render a complete page.
Applicability to the Web
SpeedReader aims at improving users’ experience on the web but is not intended to be used across the entire web, so its usefulness is bounded by the number of websites that users visit which are readable.
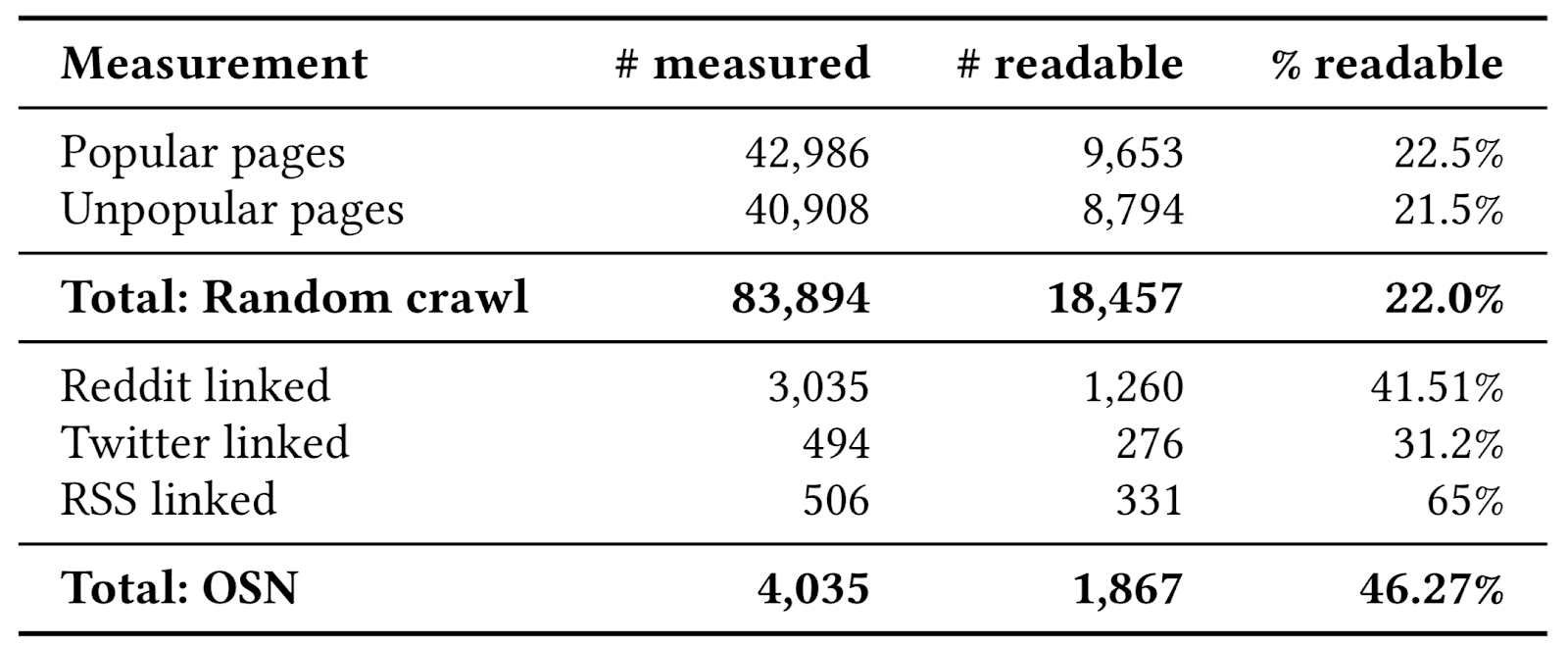
For a comprehensive view of SpeedReader’s applicability, we looked at how many pages our classifier labels as readable across five sets of pages:
- Top 5,000 Alexa domains with up to three randomly chosen pages linked from the main page, as well as following links another hop, for a total of 42,986 pages.
- Less popular Alexa domains, randomly selected among those ranked 5,001–100,000, and sub-pages collected as in the first set, for a total of 40,908 pages.
- Content linked from online discussion boards, looking at Reddit’s top 125 subreddits, and collecting shared URLs from 25 posts in each.
- Social networks, extracting shared links from tweets in the top 10 worldwide X trends.
- RSS feeds, by identifying websites among the Alexa top 1k that included RSS feeds, and fetching the five most recent pages of content in each RSS feed.
The above table summarises our findings and shows that SpeedReader is useful on 22% of pages in general, and with higher applicability for user-shared content, with 31% on X and 42% on Reddit. Finally, 65% of content published through RSS feeds appears to be readable.
Page Transduction: Radical Performance Gains
To gauge the benefits of using reader mode representation of a page, we looked at three different renderings for all the documents classified as readable above – the 18,475 unique pages. Generating a reader mode presentation of an HTML document can be thought of as translating one tree structure to another: taking the document represented by the page’s initial HTML and generating the document containing a simplified reader mode version. The new, transduced document is rendered, only fetching the remaining sub-resources and applying standard article styling.
We evaluated SpeedReader performance benefits on the entire 18,475 unique pages. To mitigate network quality and server response variations across repeated tests, we collected a replay archive for each page using the Web Page Replay (WPR) tool, which works as a proxy that responds to them as a normal web server would, instead of letting the requests through to the source. As we saw in the classifier evaluation, the speed of serving content from a replay proxy is orders of magnitude faster than downloading directly, so the measured load times primarily reflect parsing and rendering time.
We measured four performance metrics: number of resources requested, amount of data fetched, memory used and page load time. We ran all experiments on AWS m5.large instances, with one performance measurement executed at a time, per instance. For each evaluation, we fetched the page from a previously collected record-replay archive, with performance tracing enabled. Once the page was loaded and the performance metrics were recorded, we closed the browser and proxy, and started the next test. For all tests, we used an unmodified Google Chrome browser, version 70.0.3538.67, rendered in Xvfb.
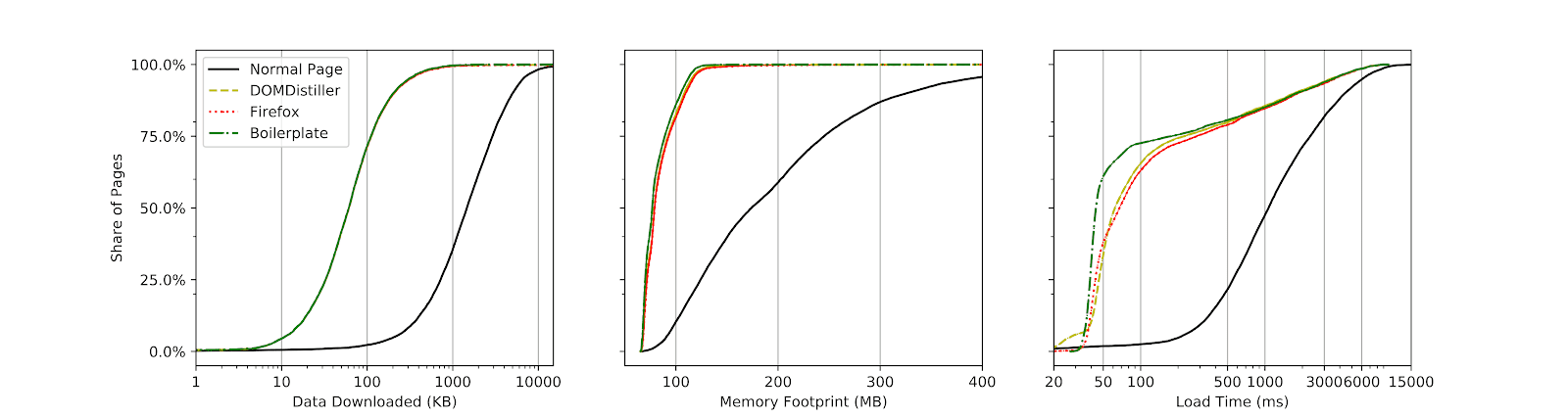
The figure shows the distributions of data downloaded, memory footprint and load time for the three evaluated transducer strategies, compared to loading unmodified pages. We also recorded the number of resources fetched for each page. It is worth noting that for memory consumption, we measured the overall memory used by the browser and its subprocesses, not just an individual page.
Despite replaying content from a local web server and using a powerful server for page rendering, unmodified page performance was less than stellar:
- 1 second median load time and 1.8 seconds on average
- 1.5 MB median data downloaded, 2.3 MB on average
- 91 median resources loaded, with 144 on average
- 174 MB of memory used, 197 MB on average
The difference between median and average values tells us that many of the heavier pages incur a big cost, skewing the average values. All three transducer strategies, on the other hand, produce gains in the same order of magnitude. Depending on the chosen transducer, we show:
- average speedups ranging from 20× to 27×
- average bandwidth savings on the order of 84×
- number of requests is reduced 51× to 77×
- average memory reduction of 2.4×
Significant Privacy Benefits
SpeedReader achieves dramatic privacy improvements, because it applies the tree transduction step before rendering the document, and thus before any requests to third parties has been initiated. The privacy improvements gained by SpeedReader are threefold then: a reduction in third parties communicated with, a reduction in scripts executed (an often necessary, though not sufficient, part of fingerprinting online), and a complete elimination of ad and tracking related requests (as identified by EasyList and EasyPrivacy). This last measure is particularly important, since 92.8% of the 18,475 readable pages in our data set loaded resources labeled as advertising or tracking related by EasyList and EasyPrivacy.
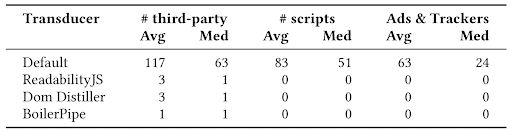
We measured the privacy gains provided by SpeedReader by first generating reader mode versions of each of the readable pages in our dataset, and counting the number of third parties, script resources, and ad and tracking resources in each generated reader mode page. We determined the number of ad and tracking resources by applying EasyList and EasyPrivacy with an open-source ad-block Node library to each resource URL included in the page. We then compared these measurements to the number of third-parties, script units, and ad and tracking resource requests made in the typical, non-reader mode rendering of each URL.
We found that all three of the evaluated tree transduction techniques dramatically reduced the number of third parties communicated with, and removed all script execution and ad and tracking resource requests from the page. Put differently SpeedReader is able to achieve privacy improvements at least as good, and almost certainly exceeding existing ad and tracking blockers, on readable pages.
Conclusion
Unique among reader mode tools, SpeedReader determines if a page is readable based only on the page’s initial HTML, before the HTML is parsed and rendered, and before sub resources are fetched. Our classifier runs within 2 ms with 91% accuracy, making it practical as an always-on part of the rendering pipeline, transforming all suitable pages at load time. We find that SpeedReader is widely applicable when combined with an accurate classifier, and can deliver in performance and privacy improvements to 22% of pages on popular and unpopular websites, and a larger proportion of pages linked from online social networks like Reddit (42%) and X (31%).
Because SpeedReader makes its modifications before sub-resources are fetched, SpeedReader on average uses 84× less network than traditional page rendering (and current reader mode techniques). This results in page load time improvements, important in a range of scenarios from poor connectivity or low-end devices, to expensive data connectivity, or simply wanting a clean and simple interaction with primarily textual content. SpeedReader also delivers page loading speedups of 20× – 27× and an average memory reduction of 2.4×, while maintaining a pleasant, reader mode style user experience.
Finally, we find that SpeedReader excels at protecting user’s privacy by removing all currently recognized third-party trackers and ads from the tested pages. When applied to our test set of 18,475 readable webpages, SpeedReader prevented 100% of advertising and tracking related resources from being fetched (as labeled by EasyList and EasyPrivacy).
SpeedReader aims at improving users’ experience on the web and is complementary to other approaches. For instance, Google Chrome has several interventions, including one that can replace images with placeholders and one that bypasses web fonts on slow connections. A more controversial intervention (in preview only yet) is Chrome’s NOSCRIPT: one that would disable JavaScript altogether on slow networks. Brave’s Shields are another example of a browser intervention that is aimed at creating a better user experience. Solutions like progressive enhancement, if employed by publishers, can yield some of the same benefits by effectively adapting the content delivered to the users. HTTP Client Hints and the Network Information API, have been introduced to provide details like the effective network type to the publisher, along with user preferences to “Save-Data” or device capabilities. However, there appears to be very limited adoption of those techniques, so we look forward to implementing SpeedReader in future versions of the Brave browser to improve the user experience when these aforementioned optimisations are not present or not sufficient.




