Brave Improves Its Ad-Blocker Performance by 69x with New Engine Implementation in Rust
This blog was written by Dr. Andrius Aucinas, performance researcher at Brave, and Dr. Ben Livshits, Brave’s Chief Scientist.
Brave Shields, which protect users’ privacy from trackers and ads, are one of the cornerstone components of the browser involved in handling every single web request made for loading a website. Since loading an average website involves 75 requests that need to be checked against tens of thousands of rules, it must also be efficient. Even though Brave’s ad-blocker was already implemented in heavily optimized C++ handling requests with sub-millisecond overhead, we found that we can further optimise it for a 69x average improvement. Starting today, this new implementation is available in our Dev channel and Nightly channel.
The recent Chromium’s Manifest v3 controversy around the overheads of the various extensions using the WebRequest API to inspect and potentially block undesired requests did not affect Brave as requests are processed natively, deep within the browser’s network stack. Nevertheless, the argument of the popular ad-blockers being very efficient made by our friends at Cliqz also pointed out that ours could be made faster still.
Brave’s network request ad-blocker supports Adblock Plus (“ABP”) filter syntax and we have previously looked at how the cost of ad-blocking adds up with the popular ad-blocking lists growing, often without the rules actually being used. Beyond the obvious hardware (e.g. phone or laptop) speed, the key factors that affect request processing time are:
- Number of rules that need to be checked before a request is blocked or accepted, e.g. how many rules need to be checked without a match before a matching one is found
- Complexity of a rule being evaluated, e.g. the more generic ones matching arbitrary patterns within a URL require more involved matching than a simple string search
Our previous algorithm relied on the observation that the vast majority of requests are passed through without blocking. It used the Bloom Filter data structure that tracks fragments of requests that may match and quickly rule out any that are clean. Alas, blocked trackers are not that uncommon. We reused the dataset from Cliqz ad-blocker performance study that collected requests across top 500 domains and up to 3 pages of each domain. Out of the 242,944 requests, 39% were blocked when using the popular combination of EasyList and EasyPrivacy.
We therefore rebuilt our ad-blocker taking inspiration from uBlock Origin and Ghostery’s ad-blocker approach. This focuses on a tokenization approach specific to ad-block rule matching against URLs and rule evaluation optimised to the different kinds of rules. We implemented the new engine in Rust as a memory-safe, performant language compilable down to native code and suitable to run within the native browser core as well as being packaged in a standalone Node.js module. Overall, we found that:
- The new algorithm with optimised set of rules is 69x faster on average than the current engine.
- For the popular filter list combination of EasyList and EasyPrivacy it achieves class-leading performance of spending only 5.7μs on average per request.
- An additional benefit of having the blocker built into the core of the browser is even less work duplicating what the browser already does, e.g. for URL parsing. With this information already available, our browser-focused API provides still better performance, cutting average request processing time down to 4.6μs.
- The new engine already supports more of the filter rule syntax that has evolved beyond the original specification, which will allow us to handle web compatibility issues better and faster.
For performance measurements in this study we used a 2018 MacBook Pro laptop with 2.6 GHz Intel Core i7 CPU and 32GB RAM.
An Overview of Ad-Block Rules
Brave’s network request ad-blocker supports Adblock Plus (“ABP”) filter syntax, so you can refer to existing filter syntax documentation from Adblock Plus web site and ABP’s filter cheatsheet. The syntax is very flexible and allows from very broad to very narrowly-targeting. The distinct types of rules include:
- Basic patterns, matching as substrings anywhere in the request URL. For example, rule
/ad/popup.would match any address that contains the exact characters. - Patterns with wildcards, broadening the simple rule’s scope. For example
/ads/banner*.gifwould match any address that contains anything in between/ads/bannerand.gif, helping e.g. with banners that have identifiers attached to them. Such rules are interpreted as simple regular expressions. - Domain-specific rules such as
||ad-delivery.netwould match for all requests sent toad-delivery.net. This particular rule does not consider what else there might be in the request URL and would block all requests to the domain, but it can be combined with the other patterns for more targeted blocking. - Regular expression rules that use the full power of the syntax – they can be very versatile but are generally also computationally expensive to match and are used sparingly. One such complex example is:
/http://[a-zA-Z0-9]+\\.[a-z]+\\/.*(?:[!"#$%&'()*+,:;<=>?@/\\^_`{|}~-]).*[a-zA-Z0-9]+/ - Exceptions – rules that tend to be used to work around specific issues caused by another, broader rule. A request that matches an exception rule should not be blocked even if it did match another rule.
Each rule can also have one or more options that define other aspects of a request, such as its type (e.g. a script, an image), domain of the page the request originated from restrictions (either limiting the rule’s use to specific domains, or applying it all but the specified domains), whether the request is first-/third-party (being sent to the same party the site itself is hosted by) and a bunch of others. The most popular ad-block lists contain tens of thousands of rules: EasyList alone has almost 40000 network rules. When each network request needs to be checked against the huge lists, the number and complexity of rules quickly add up as we wrote before.
The New Algorithm
One key aspect of the faster algorithm boils down to quickly eliminating any rules that are not likely to match a request from search. To organise filters in a way that speeds up their matching, we observe that any alphanumeric (letters and numbers) substring that is part of a filter needs to be contained in any matching URL as well. An exception to this is when a substring is immediately preceded or followed by a wildcard (*) or the network filter rule is a full regular expression. We take all such substrings and hash each of them to a single number, resulting in a number of tokens.

The numeric tokens make for easy and fast matching when a URL is tokenized in the same way. Even though by nature of hashing algorithms multiple different strings could hash to the same number (a hash collision), we use them to limit rule evaluation to only those that could possibly match. For rules that include a specific hostname, we tokenize it as well. Finally, if a rule contains a single domain option, making it only apply there, the entire domain is hashed as another token.

This tokenization process does not generate a single token for some rules. For such rules we check the domain options again if there are no negative domain options (making the rule apply to all but those domains), we hash each of the positive domain options as a token. If there are still no tokens for a rule, we use a special token 0 to identify those rules – they would potentially need to be checked for every URL.
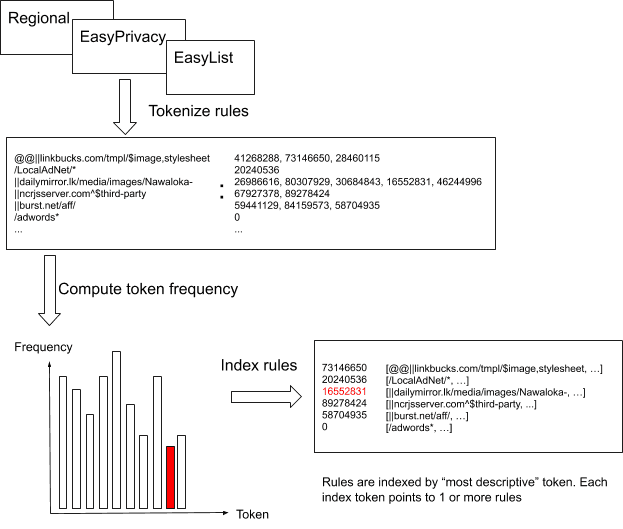
Since certain tokens like com or net are very common, we could end up matching a large number of rules for most URLs again. However, another observation is that for a rule to match a URL, every token in the rule needs to be included in the URL’s tokens. We can therefore cluster rules as defined by the least popular token. More specifically, we calculate a histogram of token popularity across all network filters and for each rule choose the least popular token as the one identifying the rule. Finally, rules are handled in 4 different ways depending on their type:
- Important rules are processed first – if any important rule matches, the request is considered blocked without checking anything else.
- Otherwise, check Redirects as they need a separate step to work out the correct resource to redirect to.
- Finally, if neither of the previous cases matched, check all remaining filters.
- If any rule in step 2 or 3 matched, check Exceptions. A match with an exception negates the match and such request should not be blocked.
Since the handling by type happens in distinct phases, the rule clustering described above is performed separately for each type.
Rule Matching
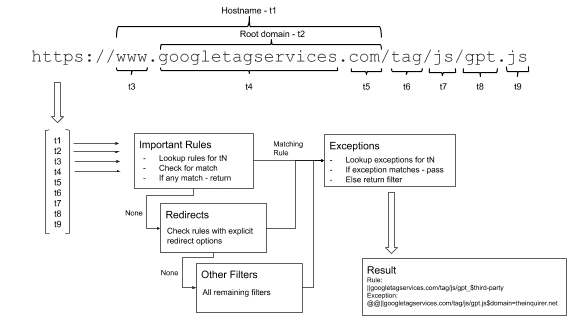
With all the tens of thousands of filters neatly organised into buckets, what do we do when checking if a URL matches any rule? Firstly, the URL is parsed by the ad-blocker and tokenized. Without relying on the information that may already be available in the browser core and allowing to skip some of the steps, the engine accepts the request URL, the source/originating frame (generally the website the request was made from) URL, and the type of the request. Request parser then:
- Extracts URL scheme (e.g.
http://) and hostname for both URLs - Extracts
rootdomain from the hostname. Root is the first subdomain after the effective top-level domain, defined by the Public Suffix List for both URLs - Compares the extracted hostnames and domains to decide if the request is first- or third-party
- Records whether the request is
httporhttpsfor specific option matching - Hashes the originating frame hostname and root domain for option matching
- Tokenises the request the same way as network filter rules, and hashes source hostname and domain
With all the preparation done, the actual matching becomes quite straightforward. Taking the extracted URL tokens one by one, the algorithm:
- Looks up the cluster of rules identified by the token
- For every rule in the custer, it checks rule options such as the type of request http/https, first-/third-party and domain restrictions. If all
optionsmatch, the filter part of the rule is checked, processing hostname checks, regular expressions and simple string search - As soon as there is a single match it stops and return the match – the earlier a rule is matched, the faster the whole process finishes
- If the algorithm doesn’t find any match for the token, it takes the next token and goes back to step 1
- Finally, if there is no URL token left, the algorithm checks all rules in the
0bucket (those with no token extracted) and returns the match if any. Otherwise the request should not be blocked
Evaluating the Performance
To evaluate performance we used the dataset published with the Ghostery ad-blocker performance study, including 242,945 requests across 500 popular websites. We tested the new ad-blocker against the dataset using different ad-block rule lists, and found that with the biggest list, combined EasyList and EasyPrivacy, it offers a 69x improvement over the average matching time, cutting the average request classification time down to 5.7μs. We measured performance of the engine using Criterion library for benchmarking. You can read more about the methodology used by the tool, however in a nutshell it is geared towards filtering out outliers by progressively expanding the number of measurement samples it collects for each iteration of evaluation. All the benchmarks were performed on the adblock-rust library version 0.1.21, using a 2018 MacBook Pro laptop with 2.6 GHz Intel Core i7 CPU and 32GB RAM, and benchmarking code can be found in the same repository.
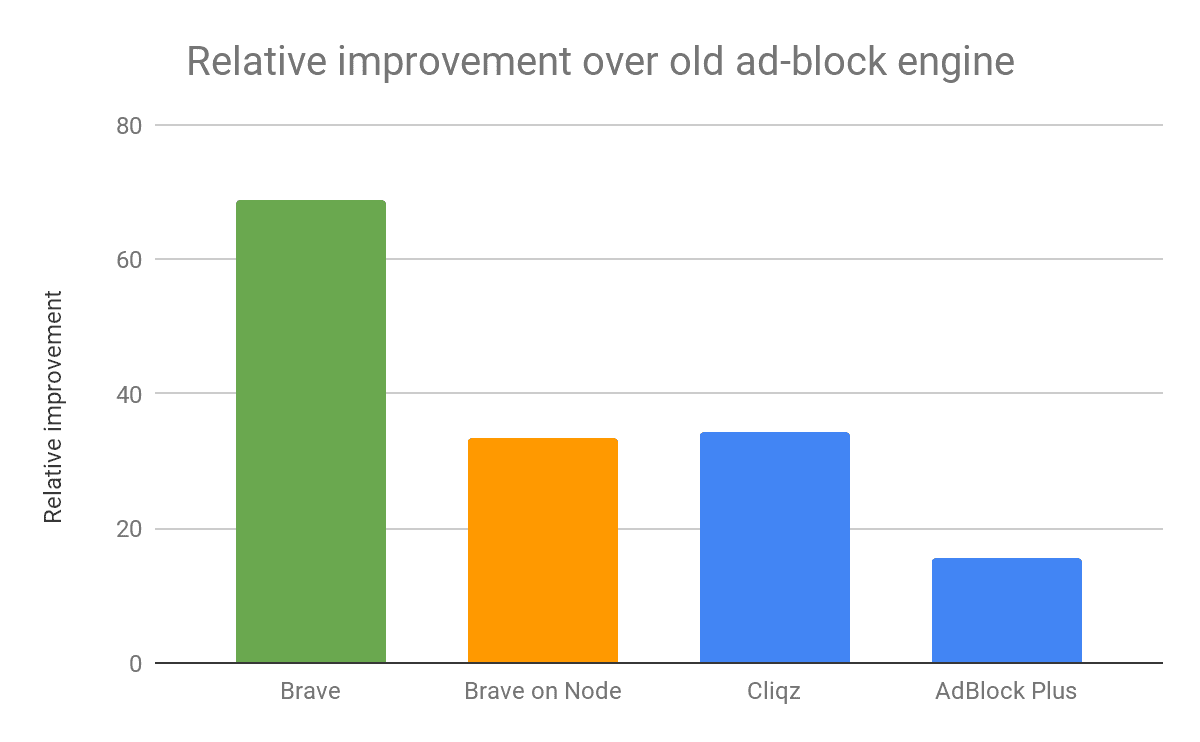
The green bar in the chart represents performance measurement from the native Criterion benchmarks using a combined rule list of EasyList along with EasyPrivacy. We also repeated the test using the tools already provided in the Cliqz study, shown in orange (for Brave) and blue (for other ad blockers) in the chart. This demonstrates that Node.js native code invocation has non-trivial overheads itself when applied to operations that only take microseconds: using Node.js setup our ad-blocker runs a lot slower and is on the same ballpark as Cliqz.
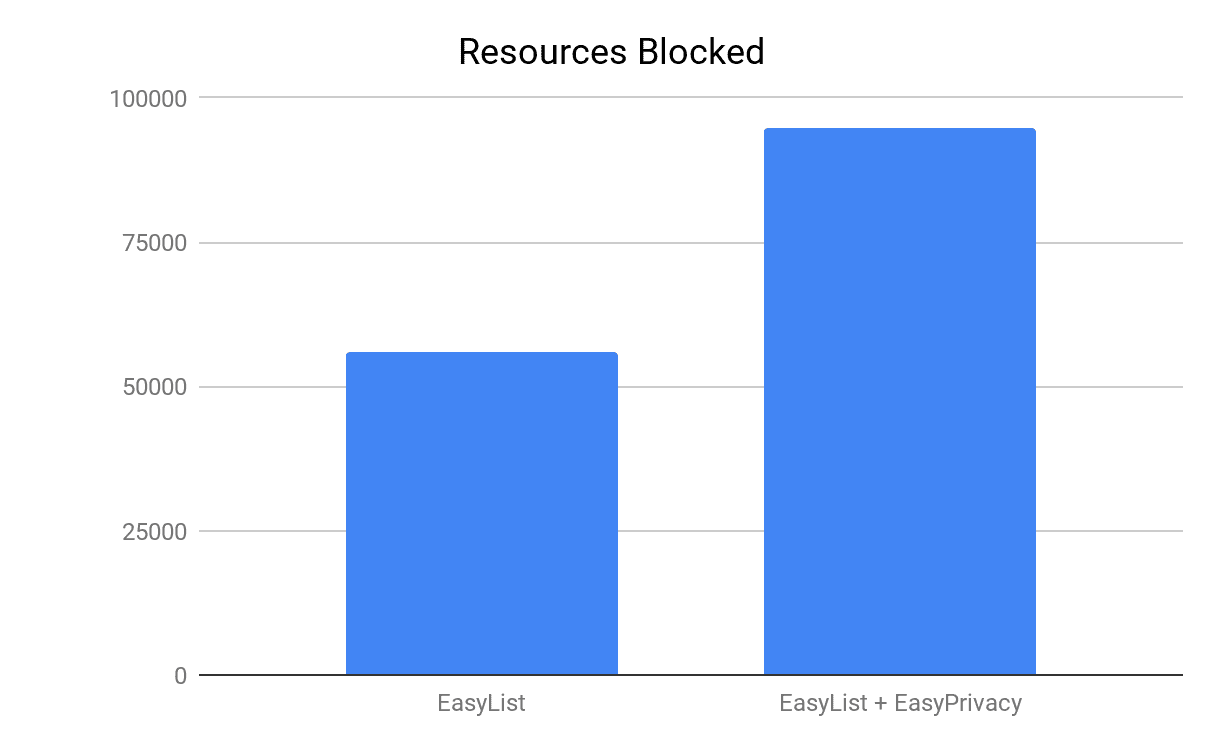
Both EasyList and EasyPrivacy filter lists are commonly used by most of the ad blockers and we actively support their maintenance. EasyList is the primary filter list that removes most adverts from international webpages, including unwanted frames, images and objects, and has almost 39,000 network filtering rules. EasyPrivacy aims to remove all forms of tracking from the internet, including web bugs, tracking scripts and information collectors, thereby protecting your personal data. EasyPrivacy provides more than 16,000 additional network filtering rules for a combined total of more than 55,000 rules. The effects of using just one or both of the lists are illustrated in the chart above: EasyPrivacy blocks 70% more requests than EasyList alone, or 39% of total requests in our test – speaks of how widespread user tracking is on the web!
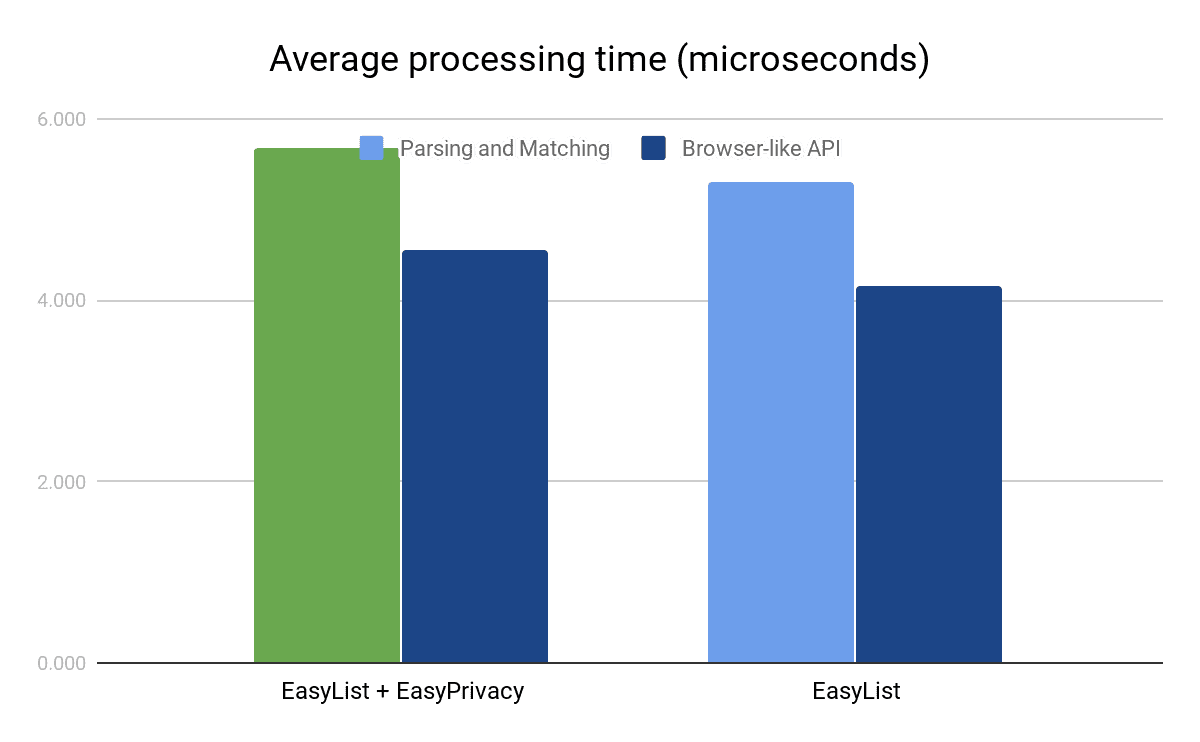
Both the size of the block list as well as the specific API used have some effects on the time taken by the ad-blocker. Addition of EasyPrivacy adds very little cost to request classification for the new ad blocker, but as highlighted above the native benchmarks alone indicate 51% lower average processing time than when using Node.js. The way ad-blocker is integrated in Brave allows us to do even less work in preparing the request for matching: the request hostname and decision whether it is first- or third-party with respect to the originating frame is already provided. This saving depends on the number of requests processed rather than the number of rules, so in our benchmark it saves another 1.1μs, or 20% in the case of full EasyList + EasyPrivacy. Overall, we end up with just 4.6μs request processing time on average for the full set of rules.
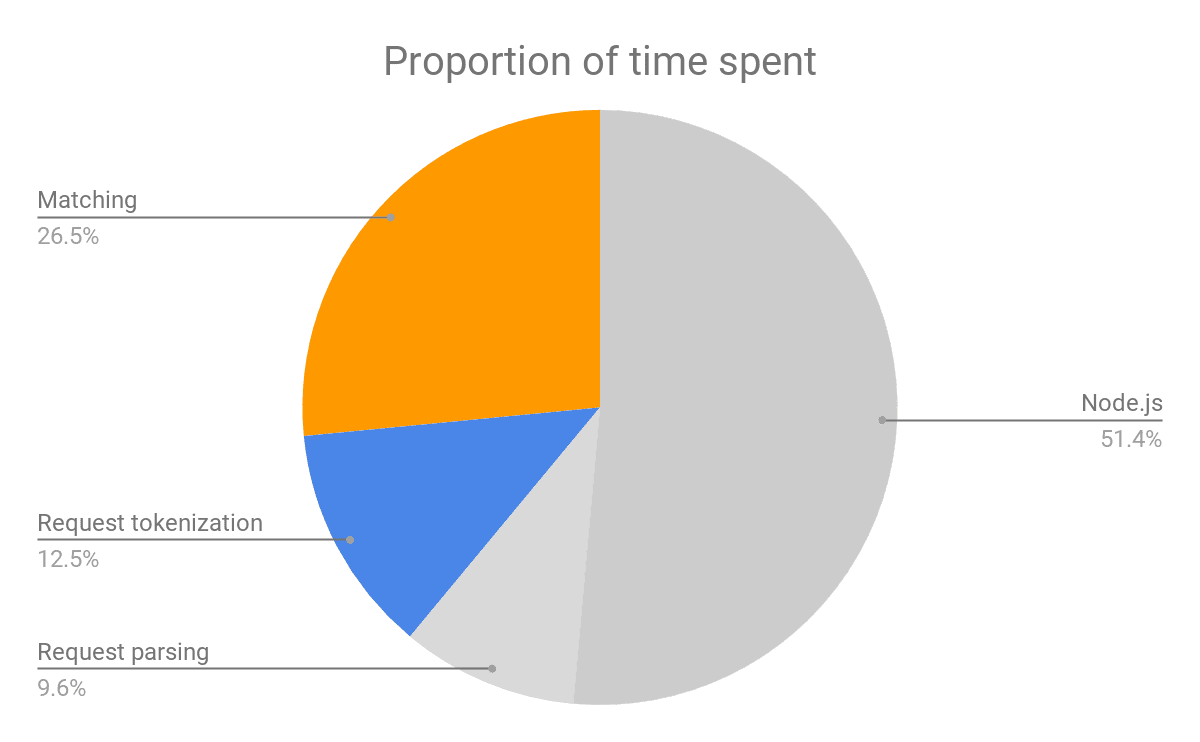
Combining the above measurements into a single cost breakdown we show that only 39% of the time reported by Node.js benchmark is spent on critical operations when using the API targeted for the browser. With the grayed-out components of the cost disappearing within the browser core, the overhead of ad-blocking goes goes down to the best-in-class by some margin.
Conclusions
Brave is loved by our community for its speed, and while a lot of the improvements come from throwing out the likes of trackers and ads, we always try to make sure every component of the browser is engineered well and has minimal overheads. Although most users are unlikely to notice much of a difference in cutting the ad-blocker overheads, the 69x reduction in overheads means the device CPU has so much more time to perform other functions.
Secondly, the context in which ad-blocker runs matters: deeper integration within the browser means that we can run optimised, native code, and that there are less overheads of propagating request information across multiple processes up to an extension. But because the browser already does some of the work useful for the ad-blocker, we can avoid duplicating it and further reduce the overheads, resulting in an ad-blocker with the best in class performance.
Finally, outside the focus of this post, the new blocker also supports more of the blocking rules. The improved functionality will help us reduce website breakage occurring due to aggressive blocking and anti-adblock measures in the coming weeks and months. In fact, these efforts are already underway, so keep an eye out!




