Understanding Redirection-Based Tracking
This blog post describes ongoing work conducted at Brave by Peter Snyder and Ben Livshits. It is the third in a series of research-oriented posts that share both present investigations and future vision. We are constantly looking to improve and automate the privacy protections in Brave. Our previous posts outlined efforts to detect and prune stale filter rules from Brave’s blocking protections, and detailed a machine learning approach to ad blocking.
Introduction: What is Redirection-Based Tracking?
Online tracking has emerged as a major privacy challenge for users. Redirection-based tracking is a technique that records and shares information about your browsing patterns. It occurs when a website instructs your browser to automatically visit a series of websites. This allows these websites to read personalized referrer headers and URL parameters, which allows them to observe parts of your browsing history and save it in the browser using cookies and local storage.
Redirection-based tracking can be performed in first or third party contexts. Third-party redirection-based tracking is more common because it can be done without any signal to the browser user. However, due to privacy protections like those in Brave (and other privacy-minded tools), some trackers have begun moving to first-party techniques.
Intelligent Tracking Prevention (ITP 2.0) has recently been proposed as a way to mitigate redirection-based tracking. As of this week, ITP 2.0 is now available in Safari Technology Preview 62. This post presents the results of an investigation we did at Brave to understand the state of redirection-based tracking online, in both the third and first party contexts. We would be happy to share the data described here (please contact us at press@brave.com).
Our Measurement Methodology
This section describes our methodology for measuring redirection-based tracking online. The following subsections describe our automated recording crawler, followed by the dataset we deployed the crawler on, and finally how we used the recorded data to understand redirection-based tracking online.
Web crawling. We built a Puppeteer based crawler that interacts with websites and keeps track of what domains forward requests to other domains. The crawler follows a “random walk” strategy to traverse the web, and operates as follows:
- Navigate to a URL.
- The crawler notes if the browser is automatically redirected to another domain, either through a HTTP 3XX header, HTML metatag instruction, or JavaScript executing on the page. If so, the redirection is recorded and the above process starts over.
- The crawler pauses for 10 seconds, observes what iframes are created on the page, and records the chain domains of each iframe requests.
- After 10 seconds, the crawler collects all of the anchor tags on the page (in both parent and child frames) that have a non-empty “href” attribute. The crawler then clicks on the selected links until the page is redirected, selecting first from anchors pointing to remote domains, and then the same domain. If the page changes, then the process continues from step 1, otherwise the crawler exits.
The crawler continued the above process until it had run to completion (i.e. exited from step 4), or for 4 minutes, whichever occurred first. All crawls were conducted on AWS infrastructure, and performed from known AWS IPs.
We treated the global Alexa 10k as fairly representative of the web in general. We are considering crawling different regional and “top” lists, but those measurements are not part of this posting. For each crawl, we randomly selected one URL from the Alexa 10k. Because of the large number of crawls (we conducted 50,980), we selected each site in the Alexa 10k multiple times. This was intentional, since our random walk strategy meant that a very different set of domains and URLs might be visited from multiple initial seed URLs.
Graph analysis. We modeled our results as a graph, with nodes representing domains visited during the crawl, and edges representing frame-level requests (i.e., the initial request for content for each frame, and not for page level requests for images, Ajax requests, or similar). Each edge travels from the node representing the domain where the request initiated, and travels to the node representing the domain that served the response.
Each edge was labeled as either a “navigation” edge (meaning that the frame’s URL change was the result of the crawler clicking on a link) or a “redirect” edge (meaning that the frame’s URL changed without any user interaction). We also annotated each edge with information regarding whether the URL request was made by the top level frame, or an iframe, which frame made the request, and a unique identifier for each crawl session, in order to to allow us to recreate each crawl session.
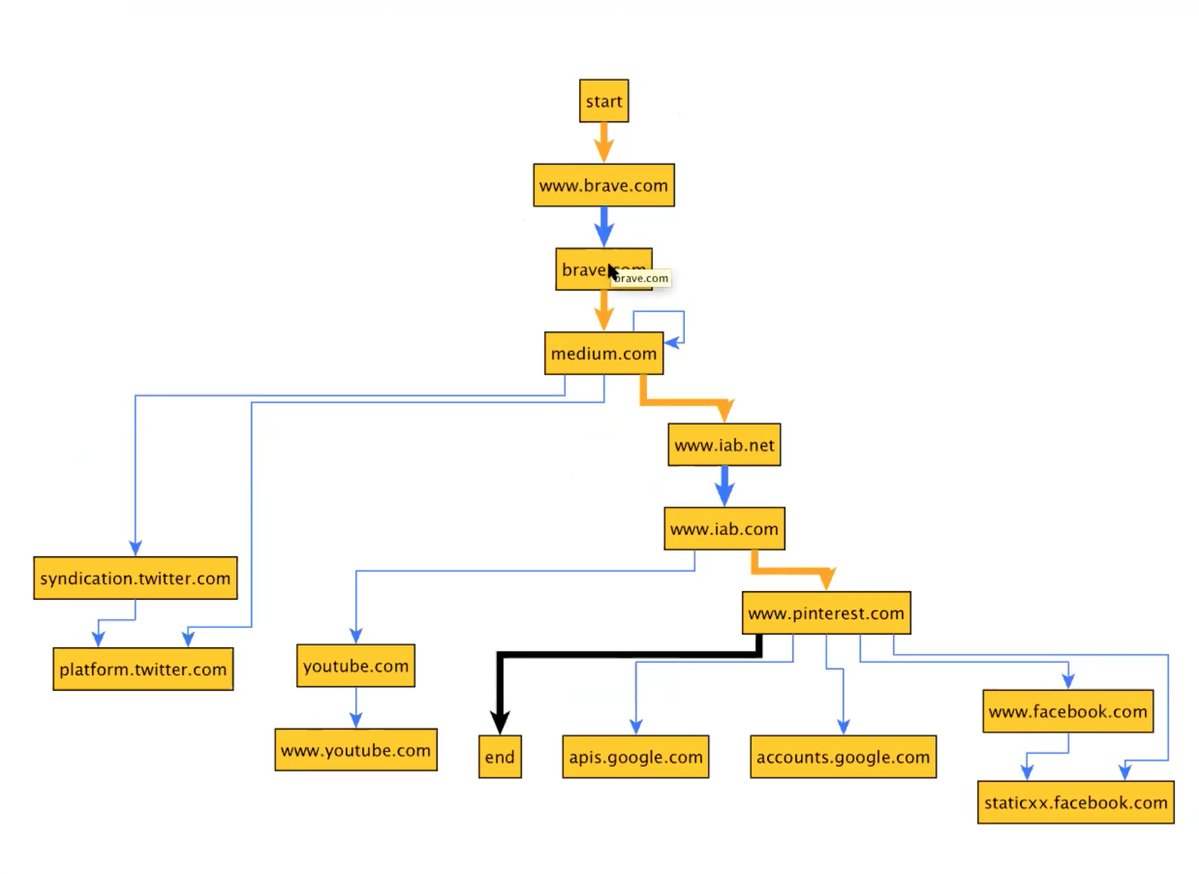
The above image shows a representative subgraph collected in this work. Thick arrows show the requests made by the top-level viewport frame of the browser, and thin arrows show resources requested in iframes. Orange arrows are navigations initiated by mouse clicks, and blue arrows are requests made without any crawler interaction. The above depiction is incomplete, though; the full captured graph annotates each edge with additional information, including the URL requested, timestamps, and frame identifiers.
Interpreting Crawl Results and Analyzing Graphs
This section describes the results of executing the above crawl 50,980 times. The resulting data set encompasses 765,687 frame-level requests, made to 47,130 unique domains. The rest of this section describes how we used this dataset to measure first- and third-party redirection-based tracking.
Also of interest, we observed 26 domains matching [0-9]+.umprow.com appear as a first-party redirector in our crawls. On manual evaluation, we discovered that the site is malicious and used in browser hijacking. This unexpected result suggests that the types of measurements described in this post can help identify other types of web malfeasance beyond privacy violations.
Understanding Third Party Tracking
| Rank | Redirecting Domains | # Domains Directed To | Receiving Domains | # Domains Directed From |
|---|---|---|---|---|
| 1 | x.bidswitch.net | 39 | optout.aboutads.info | 175 |
| 2 | staticxx.facebook.com | 23 | www.youronlinechoices.com | 103 |
| 3 | match.adsrvr.org | 22 | preferences-mgr.truste.com | 92 |
| 4 | ib.adnxs.com | 19 | x.bidswitch.net | 32 |
| 5 | cm.g.doubleclick.net | 13 | image2.pubmatic.com | 22 |
| 6 | em.baidu.com | 12 | match.adsrvr.org | 20 |
| 7 | image8.pubmatic.com | 11 | simage2.pubmatic.com | 19 |
| 8 | fls.doubleclick.net | 11 | www.ddai.info | 14 |
| 9 | bh.contextweb.com | 11 | s.amazon-adsystem.com | 12 |
| 10 | secure.adnxs.com | 8 | contextual.media.net | 9 |
Third-party redirection-based tracking occurs when embedded frames engage in redirection chains to persist and share your browsing behavior with other parties. We observed 7,048 domains included by the top level document in iframes (i.e. the initial domain requested by each iframe), 6,701 of which immediately redirected to at least one additional domain. The above table shows the 10 most popular domains that redirected to other domains in iframes. We note that all third parties, including the above, are prevented from storing state in Brave by default.
We also measured which domains were most frequently redirected-to in iframes. These parties are frequently data aggregators or ad servers. We observed 202 domains that appeared in the crawl only when being redirected to iframes. The 10 domains most frequently redirected-to in iframes are also noted in the above table.
Our data set also allows for measuring other interesting questions about third-party redirection-based tracking, such as how deep iframe redirection chains go, or which data aggregators collaborate. We are considering many similar questions as we continue with this work.
Understanding First Party Tracking
| Domain | Alexa Rank of (eTLD+1) | # Domains Directed To |
|---|---|---|
| t.co | 37 | 2397 |
| plus.url.google.com | 1 | 390 |
| bit.ly | 13,369 | 219 |
| ow.ly | - | 58 |
| away.vk.com | 17 | 38 |
| an.yandex.ru | 23 | 36 |
| buff.ly | 1,386,408 | 33 |
| t.umblr.com | 667 | 23 |
| pass.tmall.com | - | 19 |
| eepurl.com | 745,991 | 18 |
First-party redirection-based tracking occurs when websites redirect users through a series of websites without the user’s interaction, so that the first-party domains can each record information about the user’s behavior for tracking and advertising purposes. This process is similar to the third-party case discussed above, but is conducted in the top level frame (instead of in embedded iframes), in an effort to escape privacy-protecting restrictions web browsers and privacy tools imposed on third level domains.
We observed 37,280 domains visited in the top level frame, 18,531 of which automatically redirected the crawler to another domain. However, not all of these redirections are the result of tracking or malicious purposes; there are many cases where domains automatically forward to another domain for non-malicious purposes. For example, a website might want to host all of its content from a single subdomain (e.g. example.org → www.example.org). Similarly, websites migrating to a new domain might wish to automatically redirect all users to their new domain (e.g. old.org → new.org), or redirect to a more secure protocol (e.g. http://example.org → https://example.org).
In order to account for such cases, we considered a domain as involved in first-party redirection-based tracking only if all of the following conditions were met:
- The domain was visited in the top level frame.
- The browser was never directed away from the domain by clicking on a link in the data set.
- The browser was automatically directed to at least two different domains from this domain in the data set.
Using the above heuristic, we observed 365 domains engaged in first-party redirection tracking. The most popular of these first-party redirectors are presented in the above table.
We note that first-party redirections like this can be done for a variety of purposes, from cookie-linking to user convenience. As other researchers have pointed out, URL shortening services are widely used for tracking, though how much of that tracking is done for analytics helpful in order to improve underlying service quality, and how much is done for privacy-violating purposes is beyond the scope of this post.
Conclusions and Next Steps
In this post we aimed to share some interesting and promising, albeit preliminary, results we’ve had for measuring redirection-based tracking online. Our results show that redirection-based tracking is a commonly used technique online. This is done predominantly in the third-party context, although more parties may be moving to first-party techniques in the future, to try and circumvent the privacy-preserving techniques that browsers such as Brave and Safari impose.
While our initial results seem promising, they carry some significant limitations. For example, the above technique will be unable to detect redirection-based tracking on URLs that are not linked from websites. Webmail, apps, and other services may use domain-based redirection to track users, which our approach would not detect. Similarly, our approach requires a large amount of indexing to capture first-party redirection carried out by unpopular parties (since we need to encounter unpopular domains multiple times, which is by definition difficult). Other planned research includes measuring what types of information redirection-based tracking domains store about users, grouping actors by eTLD+1 or other methods, and expanding the breadth of our crawling to include more websites as well as non-English language sites.
ITP 2.0 exists in preview versions of Safari primarily as a way to allow Safari to reduce the amount of state third parties are able to store. Brave’s policy of disallowing any third party state by default makes it already more privacy-preserving than ITP 2.0 in regards to third party redirection-based tracking. Brave users however may benefit from an ITP-like protection from first-party trackers, although their number is small. One possibility is to also block the domains we found from storing state in Brave. We are currently working on measuring the benefits and breakage that would come from such a policy.




