Using Federated Learning to Improve Brave’s On-Device Recommendations While Protecting Your Privacy
Authors: Lorenzo Minto (Machine Learning) and Moritz Haller (Data Scientist) of Brave Software
Recommender systems have become ubiquitous in today’s web. Content streaming platforms, e-commerce, and social networks all leverage some form of recommendation to personalize their services for the customer. But while recommendation can be of great benefit to the end-user—from discovering your new favorite artist to being informed of other news outlets relevant to your interests—modern recommendation engines are built by centrally collecting all kinds of user data (e.g. clicks, views, mouse scrolls) at the great expense of user privacy.
Recently, Brave introduced Brave News, a privacy-preserving news aggregator integrated into the browser. This service allows users to anonymously subscribe to RSS feeds of their favorite news outlets and stay up to date with all the latest news in a single place. The user can choose from 15 different categories of curated sources, and can easily customize their stream by adding or removing sources.
Normally, news aggregators, such as Google News or Apple News, offer news recommendation services to help users find news articles and outlets that are relevant to them. In order to do so, they build profiles of a user’s news interests based on their click behavior on the service: what you have opened, how long you stayed on one article, what you have viewed but not opened, etc. Here at Brave, we don’t believe in profiling users, which is why we have a very strict policy of not collecting any sensitive or potentially identifiable user data. So when it comes to providing recommendations in Brave News, in the interest of user privacy, we don’t do what others are doing, but instead rely on hand-crafted heuristics.
Not being able to base our recommendations off of user data greatly limits our ability to suggest relevant content to the user. Ideally, users’ devices would be intelligent enough to observe patterns in what users are interested in over time, without having to share that sensitive information with anyone else, including Brave. To this end we propose a new framework for making on-device privacy-preserving recommendations that doesn’t require user interaction data to be collected on a server. We will describe this framework in the rest of this blog post.
Note: Recently, you might have heard of FLoC (Federated Learning of Cohorts), Google’s proposal for “privacy-first”, post-third-party-cookies web advertising. That proposal has been heavily criticized for promoting a false notion of what privacy is and for ultimately being just another type of tracking (see brave.com/why-brave-disables-floc). We emphasize that the techniques and system described in this blog post are totally unrelated to FLoC, and do not expose information about your browsing interests to the websites you visit.
Federated Learning with Privacy
This work on private federated recommendation is only one example of how we intend to leverage federated learning with privacy on the Brave browser in the future. This new paradigm will enable us to offer new services such as local news recommendations for Brave News, and optimize already existing ones such as our local ads targeting machine learning. Stay tuned for more updates on this ongoing effort.
System Overview
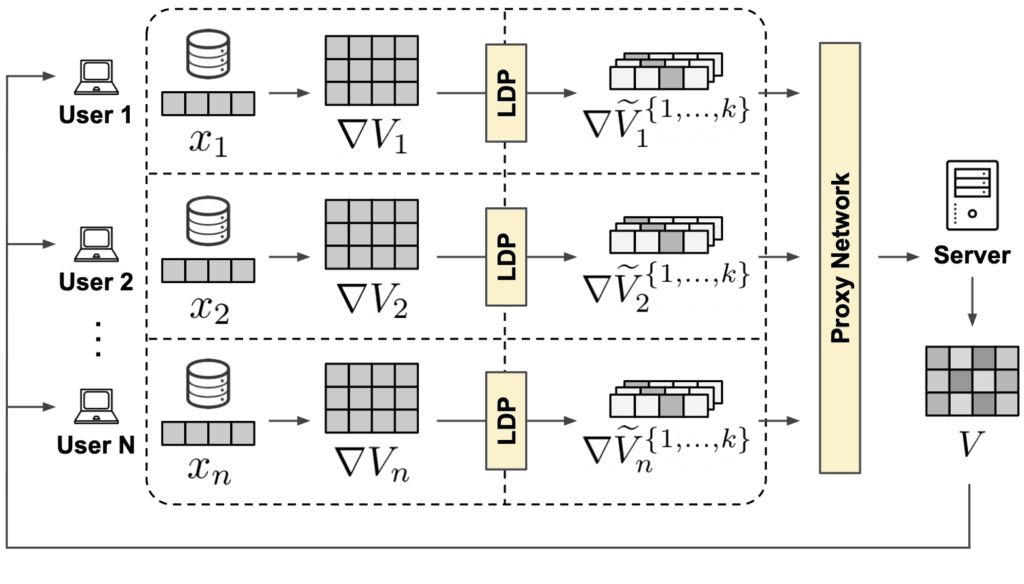
We propose a new privacy-first framework to solve recommendation by integrating federated learning with differential privacy. Federated Learning 1 has gained significant momentum in recent years. This approach allows users to collaboratively learn prediction models without the need of collecting and storing user data on a central server. Users train local models on their private data and share only their local model updates with a central server. The central server computes a global model as the aggregate of all local models and sends it back to the users, where the process repeats. In our framework we have 4 main components: Client, LDP Module, Proxy Network and Server.
Client & LDP Module
Initially, each client randomly initializes its own local user embedding $x_u$. The client is tasked with continuously processing the incoming item matrix $V$ from the server and using it to update the local user embedding and producing a local item matrix gradient update $\nabla V$. The client never shares its local user embedding with anyone. The local item matrix update is privatized by the LDP module and shared safely with the proxy network. Once the training has finished, the client can use its local embedding in conjunction with the latest item matrix received to compute recommendations on-device.
Proxy Network
Once the privatized updates reach the proxy network, these are stripped of their metadata (i.e. IP address), split into the single updates, shuffled with the updates from other users to break any existing timing patterns and, finally, forwarded to the server. The proxy network takes care of breaking linkability between the streams of multiple updates coming from each client at each epoch. This greatly reduces the user fingerprinting surface and prevents the recommender from building any longitudinal representation of the user, both within and across epochs.
Server
At the very beginning, the server randomly initializes an item matrix, which constitutes the global part of the shared model. This is shipped to all the clients to initiate the federated learning process in epoch 0. At each epoch, once enough privatized gradient updates reach the server, they are aggregated together to reconstruct a global item matrix update $\nabla V$ . This is used to compute an updated item matrix $V^{\prime}$, which is then shipped to each client to initiate the next federated learning epoch.
Making Model Updates Private
While with federated learning private user data never directly leaves the client, there still exists an outflow of information in the form of model updates from each client to the server. We choose a privatization mechanism based on local differential privacy and sparse communication to protect each user’s model updates. Differential privacy bounds the contribution of each user to the model in such a way that the model output is not revealing any particular user’s contribution.
To privatize the gradient updates before shipping them to the server we adapt to our recommendation task the randomized binary response mechanism proposed in 2. The proposed adaptation takes in the real-valued, multidimensional item gradient matrix $\nabla V$, randomly selects one item and one factor from it and encodes the selected gradient value in the transmission frequency of two opposite global constants ${B, −B}$.
The output of this mechanism $\nabla \tilde{V}$ can be represented by a simple tuple, greatly improving communication efficiency. We produce $k$ of such tuples, where $k$ is the selected number of updates contributed by each user. Increasing $k$ improves the utility of our protocol, but ultimately weakens privacy in that more information, however privatized, leaves the client at each epoch.
It is important to note that a single observation of such messages can give little to no information about the underlying parameter update of a single user. However, once aggregated at the central parameter server these updates come together to make an unbiased estimator of the item gradient matrix $\nabla V$.
Experimental Summary
Does it work?
We demonstrate the efficacy of the proposed system by plotting performance as a function of per-update privacy budget $\epsilon$, number of updates $k$, and population size. We initially focus on a small item set size of 1,000 items, as this is the easiest setting for our problem.
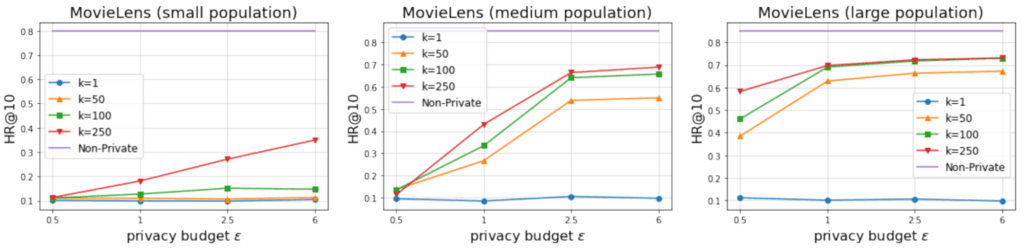
We show that we can achieve competitive performance (HR@10 $\approx$ 0.65) already for 10,000 users and per-update privacy budget 2.5. When we increase participation to 50,000 users, we achieve HR@10 up to 0.7 and higher with privacy budget $\epsilon$ as little as 1.
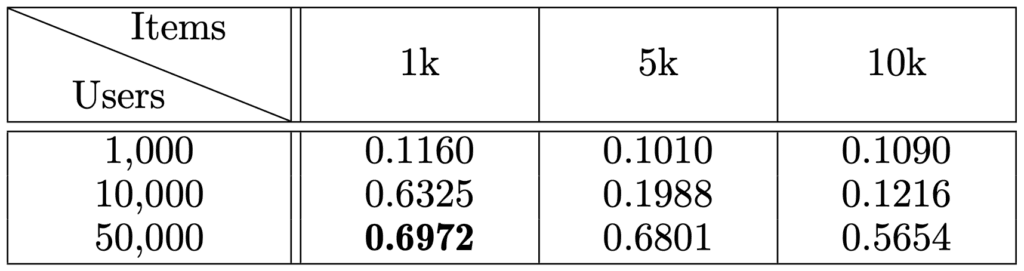
What if the item set is larger?
We extend our investigation to item sets larger than 1,000 to understand how performance evolves as the number of items considered is increased. For the small population size, barely any learning (HR@10=0.1160) is possible even on the smallest item set. For the medium population (10,000 participants) we show good utility only when considering the settings with 1,000 items, but utility decreases rapidly already when item set size is increased to 5,000. As expected, when using 50,000 participants, utility degrades slower, showing acceptable performance HR@10>0.5 across all item set sizes.
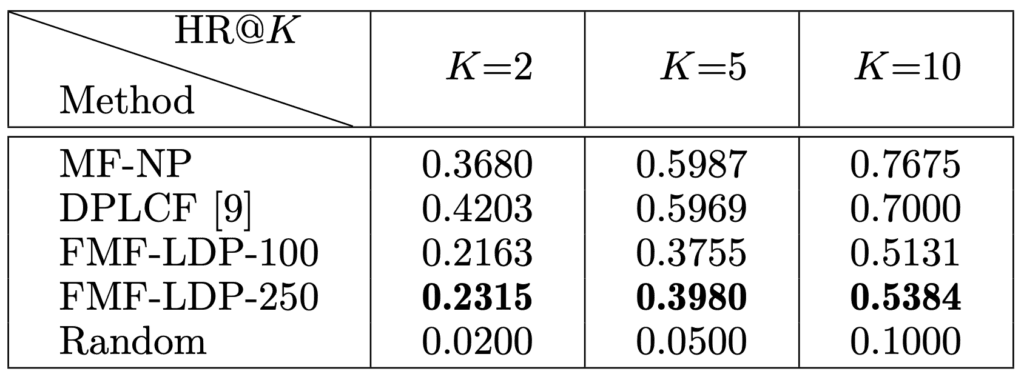
How does your system compare across various benchmarks?
We chose a random baseline model to establish the lower bound and traditional non-private matrix factorization (MF-NP) as a natural upper bound. We further compare our system with Gao et al. 3 DPLCF which, to the best of our knowledge, is the most comparable method in existing literature. Our system is denoted as FMF-LDP. We test on the full 20M MovieLens dataset.
Our system clearly outperforms the random baseline with HR@10 of 0.5 and higher, corresponding to a $5\times$ improvement, showing that it is possible to provide reasonable utility without compromising user privacy. As expected, the system does not match the performance of its non-private equivalent and also falls short of Gao et al. 3, however we argue that with more suitable user and item set cardinalities than what the off-the-shelf 20M MovieLens dataset provides, our method is in fact a competitive alternative.
Want to Read More?
To know more about the privacy risks of recommender systems we suggest the reading of Calandrino et al. 4 and Lam et al. 5. A privacy-preserving recommender system that works in similar problem setting as ours is proposed in Gao et al. 3, where the authors leverage randomised response to collect perturbed versions of user data. You can find more information in our main paper.




