Brave Research and academic collaborators design a new framework to guarantee that machine learning models were trained privately
Confidential-DPproof uses Zero Knowledge Proofs for verifiable privacy protection, and garners Spotlight award at prestigious ICLR 2024 conference
by Ali Shahin Shamsabadi, Privacy Researcher at Brave
Summary. Machine learning models trained on clients’ data without any guarantees of privacy can leak sensitive information about clients. For example, in the application of machine learning to advertising, we ideally want to learn the general patterns (“showing scientific advertisements to clients visiting scientifically related contents”), however parameters of a trained machine learning model might encode specific facts about the interest of an individual client (“Ali visited https://brave.com/research/ on 26 Feb 2024.”). Unfortunately, some institutions may not adhere to their claim of training machine learning models with client privacy
- Intentionally: not considering client privacy while training the models, or considering inadequate privacy safeguards to achieve better model utility; or
- Accidentally: hard-to-detect bugs occurred in the implementation of privacy requirements of learning algorithms.
We introduce verifiable private training (Confidential-DPproof – Confidential proof of differentially private training) which enhances training with a certificate of privacy while not revealing any information about the data and model.
Confidential-DPproof is accepted at the 12th International Conference on Learning Representations ICLR2024 as a spotlight (top 5%) paper. Confidential-DPproof will be presented at the conference between May 7th and 11th in Vienna, Austria. Confidential-DPproof is available in an open-source implementation, and can be used by institutions to offer verifiable privacy protection to clients in machine learning based products.
Why should we care about client’s privacy when training machine learning models on their data?
Machine learning models that are trained without a privacy-preserving algorithm can memorize sensitive information about their training set. Publishing the parameters, or even just the outputs, of machine learning models can consequently risk the privacy of the clients who contributed to their training process. For example,
- Membership inference attacks: exploit access to a model’s outputs to infer the presence (or absence) of a particular data point in its training set.
- Data reconstruction attacks: reconstruct the original training data points through an analysis of the model’s parameters.
How can we protect client’s privacy?
The framework of Differential Privacy is the gold standard for formalizing privacy guarantees. When training machine learning models, a Differential Privacy training algorithm provides guarantees for individuals by ensuring that data contributed by each individual client has a bounded influence on the final model in a mathematically precise manner. Therefore, absence or presence of a client will not result in a significantly different model.
Differentially Private Stochastic Gradient Descent is the canonical approach to training machine learning models with guarantees of Differential Privacy. Differentially Private Stochastic Gradient Descent imposes two main modifications to vanilla Stochastic Gradient Descent to provide differential privacy guarantees: 1) clipping per-example gradients to a fixed norm to bound the algorithm’s sensitivity to each individual client’s data (assuming each client only contributes one data point to the training); 2) adding calibrated noise to gradients before they are applied to update the model to ensure indistinguishability across updates. Training machine learning models with Differentially Private Stochastic Gradient Descent mitigates all attacks against the privacy of training data that fall within the threat model of differential privacy, including membership inference and training data reconstruction.
Why should we care about verifiable privacy?
Implementing Differentially Private Stochastic Gradient Descent training algorithms can be challenging and hard-to-detect errors can easily occur as a result of uncommon and complex modification to the underlying training optimizer. Therefore, institutions may not adhere to their claims of training machine learning models with differential privacy guarantees intentionally (e.g., if they are trying to evade privacy regulations to maximize utility) or accidentally (e.g., if there are hard-to-detect bugs in the implementation of their private algorithm). For example, see Apple’s ambiguity around not releasing the exact privacy budget of a deployed Differential Privacy mechanism and/or other relevant details: Privacy Loss in Apple’s Implementation of Differential Privacy on MacOS 10.12.
Therefore, it is important for companies or other institutions that use DP-SGD to demonstrate that they train models within the privacy constraints expressed by clients.
Confidential-DPproof framework
We designed a framework, called Confidential-DPproof, that allows institutions to directly and proactively prove to any interested party–users or customers, regulators or governments–, through the execution of a Zero Knowledge Proof protocol, that their machine learning models are trained in a privacy-preserving manner (i.e., protecting the privacy of individuals who provided their data for the training).
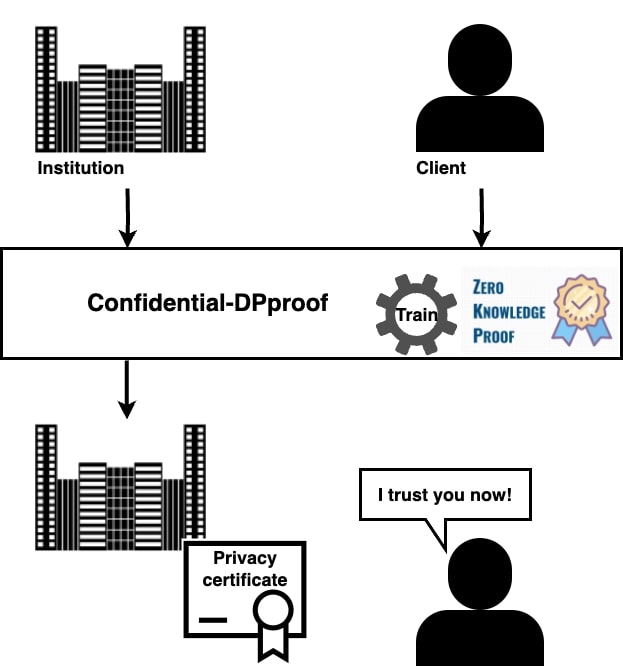
How does Confidential-DPproof work?
In our work, we propose a zero-knowledge proof protocol to proactively generate a certificate of privacy during the training process while preserving the confidentiality of all information including training data and model parameters. Zero-knowledge proof allows a party to prove statements about their private data without revealing it. Therefore, the prover’s dataset or model is not revealed to external parties.
Parties. Consider a setting with two parties, a prover and an auditor:
- The prover is an institution that wants to train a model on a sensitive dataset for different purposes such as providing machine learning based services.
- The auditor is an external entity (e.g., a user or an auditor) that aims to verify the privacy guarantees of the prover’s model.
Desiderata.
- Completeness. The auditor must infer the exact privacy guarantee and provide a public certificate of such guarantee.
- Soundness. The auditor must be able to catch malicious provers who do not adhere to their claims of training machine learning models with privacy guarantees, either intentionally or accidentally.
- Zero Knowledge. The training data and model parameters computed during training must stay confidential as institutions are not willing/allowed to share their models and data with external parties due to privacy regulations and intellectual property concerns.
Confidential-DPproof framework works as follows:
- Prover publicly announces the privacy guarantees that it is planning to provide;
- Prover and auditor agree on the Differentially Private Stochastic Gradient Descent training algorithm and specific values for its hyperparameters.
- Prover and auditor run our newly-proposed zero-knowledge protocol.
- Prover obtains a certificate for the claimed privacy guarantee.
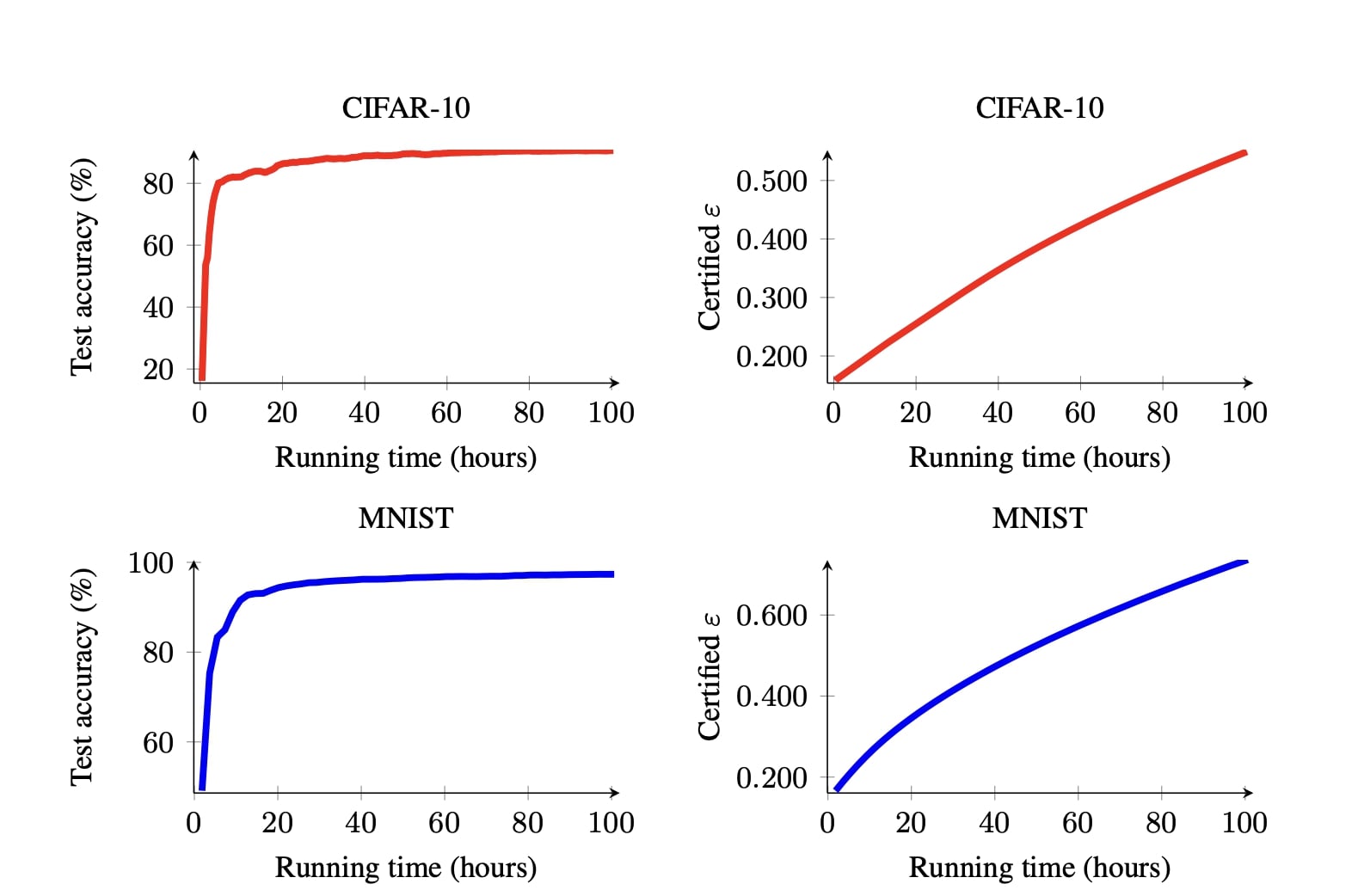
How is the performance of Confidential-DPproof?
Since we design Confidential-DPproof to enable institutions to prove the differential privacy guarantees of their model to an auditor while being able to protect the confidentiality of their data and model, our experiments consider the following questions:
- What are the best trade-offs between utility and certified privacy guarantees that Confidential-DPproof can achieve given i) the respective interests of the institution (in terms of utility); ii) the respective interests of auditor (in terms of privacy); and iii) constraints imposed by Zero-Knowledge proof regarding the complexity of models?
- What is the cost (in terms of running time) of verifying the training run while ensuring confidentiality?
Want to improve Confidential-DPproof?
Confidential-DPproof provides many benefits to institutions and their users; however, there is still room for improvement. For example, one could further extend Confidential-DPproof to prove that no adversarial data manipulation, such as sharing information across data points, was performed prior to data commitment.
Want to read more?
You can find more information in our research paper.
Acknowledgements
I would like to thank my co-authors for their feedbacks on the present blog post and for their contributions to the work presented here: Gefei Tan, Tudor Ioan Cebere, Aurélien Bellet, Hamed Haddadi, Nicolas Papernot, Xiao Wang, and Adrian Weller.




