Braveリサーチチームと学術共同研究者は、機械学習モデルが非公開でトレーニングされたことを保証するための新しいフレームワークを設計しました
Confidential-DPproofは、検証可能なプライバシー保護にゼロ知識証明を使用し、権威あるICLR 2024カンファレンスでSpotlight賞を受賞しました。
Brave プライバシー・リサーチャー Ali Shahin Shamsabadi寄稿
プライバシーの保証がないままクライアント・データで学習した機械学習モデルは、クライアントに関する機密情報を漏洩する可能性があります。例えば、機械学習を広告に応用する場合、一般的なパターン(サイエンスに関連するコンテンツを訪問したクライアントに、サイエンスに関する広告を表示する)を学習するのが理想ですが、個々のクライアントの関心に関する個別のアクション(Aliは2024/2/26にhttps://brave.com/research/ を訪問した)が機械学習モデルのパラメータとして使用されるかもしれません。残念なことに、一部の公的機関は、クライアントのプライバシーを考慮して機械学習モデルを訓練するという主張はしても、以下のような状況によりその主張を守らないかもしれないのです。
- 意図的なケース:モデルのトレーニング中に顧客のプライバシーを考慮しなかったり、より優れたモデルの実用性を達成するために不十分なプライバシー保護を採用したりした場合。
- 事故的なケース:学習アルゴリズムのプライバシー要件の実装において、検出困難なバグが発生した場合。
私たちは、データやモデルに関する情報を一切明らかにすることなく、プライバシーを保証し、トレーニングを強化する、検証可能なプライベートトレーニング(Confidential-DPproof – Confidential proof of differentially private training/プライベート・トレーニングの機密証明)を発表します。
Confidential-DPproofは第12回International Conference on Learning Representations ICLR2024にスポットライト(上位5%)論文として選出されました。Confidential-DPproofは5月7日から11日までオーストリアのウィーンで開催される会議で発表されます。Confidential-DPproofはオープンソースとして利用可能であり、公的機関が機械学習ベースの製品で検証可能なプライバシー保護をクライアントに提供するために使用することができます。
機械学習モデルの強化においてなぜクライアントのプライバシーを守らなければならないのか
プライバシーを保護するアルゴリズムなしで学習された機械学習モデルは、学習セットに機密情報を記憶してしまう可能性があります。機械学習モデルのパラメータや、もっとシンプルにモデルからの出力を公開することによって、結果として、その学習プロセスに貢献したクライアントのプライバシーが危険にさらされる可能性があるのです。例えば 、
- メンバーシップ推論攻撃: モデルの出力を悪用して、トレーニングセット内の特定のデータの存在(または非存在)を推論する。
- データ再構築攻撃: モデルのパラメータを分析することで、元のトレーニングデータを再構築する。
どのようにクライアントのプライバシーを保護できるのか?
差分プライバシーのフレームワークは、プライバシー保証を公式化するための最も標準的な方法です。機械学習モデルをトレーニングする際に差分プライバシートレーニングアルゴリズムは数学的に正確な方法で、各クライアントから提供されたデータが利用されていたとしても、最終的なモデルに与える影響は個々のクライアントに対して限定的であることを保証します。そのため、特定のクライアントが存在するかしないかで、モデルが大きく変わるようなことが発生しません。
差分プライベート確率勾配降下法(Differentially Private Stochastic Gradient Descent)は、差分プライバシー(Differential Privacy)が保証された機械学習モデルをトレーニングするための標準的なアプローチです。差分プライベート確率勾配降下法は、差分プライバシー保証を提供するために、バニラ確率勾配降下法(Vanilla Stochastic Gradient Descent)に2つの主な修正を加えます。 1)各クライアントのデータに対するアルゴリズムの感度を制限するために、サンプル毎の勾配を固定ノルムにクリッピングする(各クライアントは学習に1つのデータポイントしか寄与しないと仮定する)。2)モデルの更新に適用される前に、較正されたノイズを勾配に追加し、更新間の区別がつかないようにする。差分プライベート確率勾配降下法を用いた機械学習モデルのトレーニングは、メンバーシップ推論やトレーニングデータの再構築を含む、差分プライバシーの脅威モデルに該当するトレーニングデータのプライバシーに対する全ての攻撃を緩和します。
なぜ検証可能なプライバシーが重要なのか?
差分プライベート確率勾配降下法の学習アルゴリズムの実装は困難であり、基礎となる学習オプティマイザーに一般的でない複雑な変更を加えた結果として、検出困難なエラーが容易に発生する可能性があります。 そのため公的機関は意図的に(効用を最大化するためにプライバシー規制を回避しようとする場合など)、あるいは偶発的に(非公開アルゴリズムの実装に検出が困難なバグがある場合など)、差分プライバシー保証を用いて機械学習モデルをトレーニングするという主張を守らない可能性があるのです。例えば、差分プライバシー・メカニズムの適用における正確なプライバシーバジェットやその他の詳細を公表しないアップル社の曖昧さをご覧ください:Privacy Loss in Apple’s Implementation of Differential Privacy on MacOS 10.12
このように、差分プライベート確率勾配降下法を使用する企業やその他の機関は、クライアントが表明したプライバシー制約の範囲内でモデルをトレーニングしていることを実証することが重要です。
Confidential-DPproofフレームワーク
私たちは、Confidential-DPproofというフレームワークを設計しました。このフレームワークは、ゼロ知識証明・プロトコルの実行を通じて、機関投資家が、利害関係者(ユーザー、顧客、規制当局や政府)に対して、機械学習モデルがプライバシーを保護する方法でトレーニングされていること(すなわち、トレーニングのためにデータを提供した個人のプライバシーを保護すること)を直接かつ積極的に証明することを可能にします。
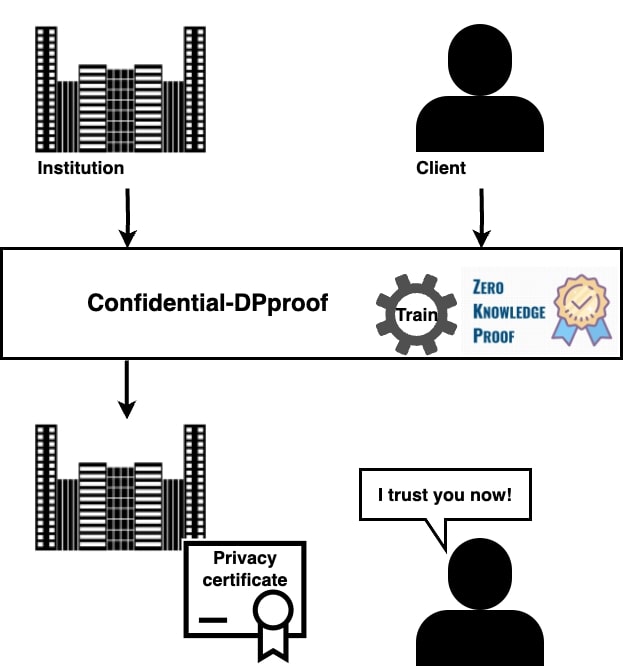
Confidential-DPproofはどのように機能するのか?
私たちの研究では、学習データやモデルパラメータを含む全ての情報の機密性を保持しながら、学習プロセス中に積極的にプライバシー証明書を生成するゼロ知識証明プロトコルを提案しています。 ゼロ知識証明により、当事者は自分の個人データを明かすことなく、その個人データに関する記述を証明することができます。そのため、証明者のデータセットやモデルが外部に漏れることはありません。
参考ケース. 証明者と監査者という二つの関係者がいる状況を考えてみます。
- 証明者は機械学習ベースのサービス提供など、さまざまな目的のために、機密性の高いデータセットでモデルを訓練したい機関です。
- 監査者は、証明者のモデルのプライバシー保証を検証することを目的とする外部のエンティティ(ユーザーや監査人など)です。
必要となる要求事項.
- 完全性. 監査者は、正確なプライバシー保証を推測し、そのような保証の公的証明書を提供しなければなりません。
- 健全性. 監査者は、意図的、事故的を問わず、プライバシーを保証した機械学習モデルを訓練するという主張を守らない悪質な証明者を摘発できなければなりません。
- ゼロ知識. トレーニング中に使用されたトレーニングデータとモデル・パラメータは、プライバシー規制や知的財産権に関する懸念から、公的機関によりモデルやデータを外部と共有することが許可されていないため、機密性を保たなければなりません。
Confidential-DPproofフレームワークによる機能は次通りです:
- 証明者は、適用される予定のプライバシー保証を公開します。
- 証明者と監査者は、差分プライベート確率勾配降下法の訓練アルゴリズムと、そのハイパーパラメータの具体的な値を確認、合意します。
- 証明者と監査者は、新しく提案されたゼロ知識プロトコルを実行します。
- 証明者は、プライバシー保証の証明書を取得します。
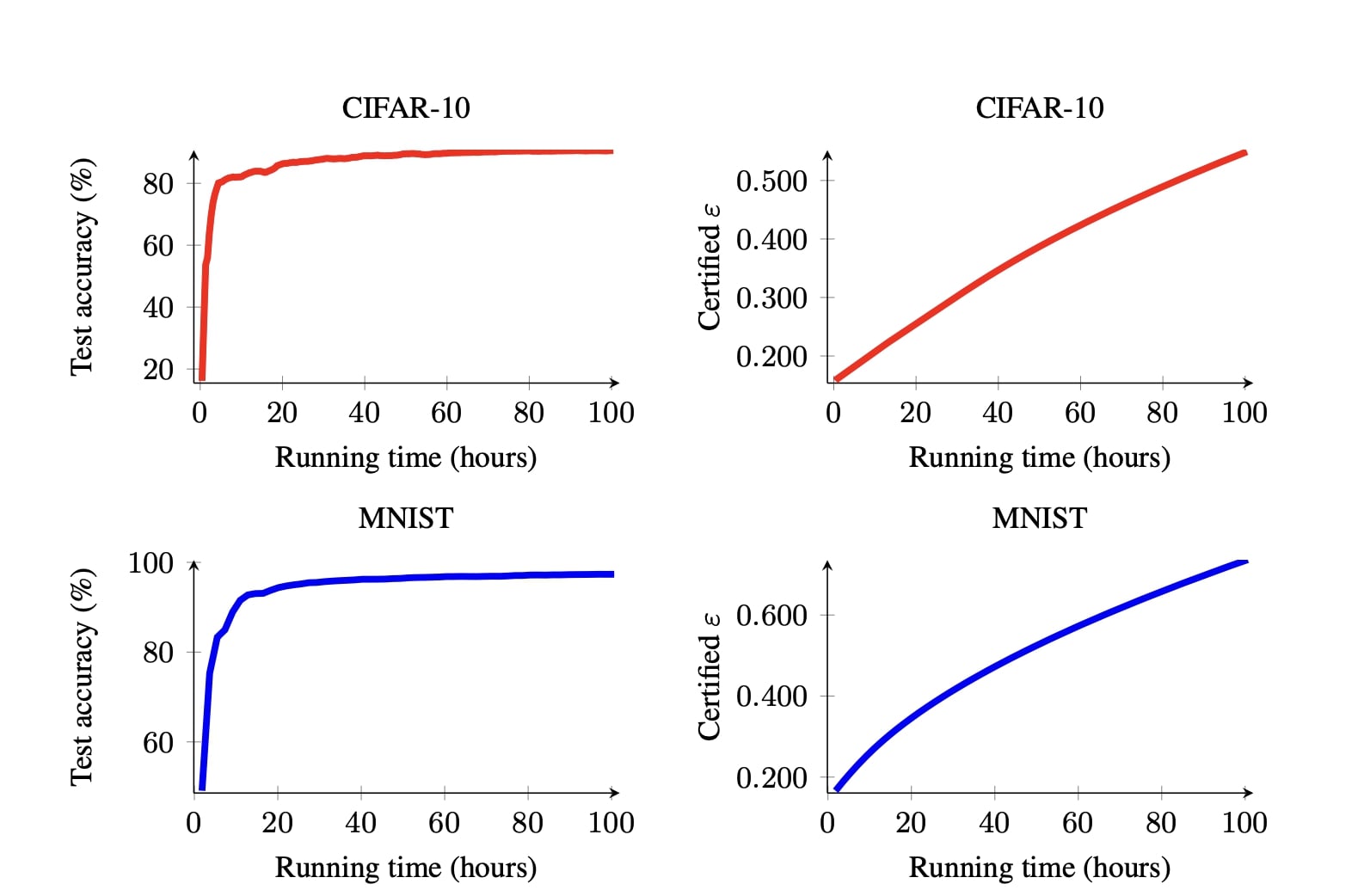
Confidential-DPproofのパフォーマンスは?
Confidential-DPproofは、各機関がデータとモデルの機密性を保護しながら、そのモデルの差分プライバシー保証を監査者により証明できるように設計されており、私たちの実験では以下の問題を考察しています。
- Confidential-DPproofが達成できる以下の3つに対して、効果とプライバシー保証との間の最良のトレードオフは何か。i) (実用性の観点で)それぞれの機関の利益。 ii) (プライバシーの観点で)監査者のそれぞれの利益。 iii) ゼロ知識証明がモデルの複雑さに対して課す制約。
- 秘密保持を確保しながらトレーニングを検証するためのコスト(実行時間)
Confidential-DPproofのさらなる改善
Confidential-DPproofは公的機関およびその利用者に多くの利点を提供しますが、まだ改善の余地もあります。例えば、Confidential-DPproofをさらに拡張して、データ・コミットメントの前に、データ・ポイント間の情報共有のような悪意のあるデータ操作が行われていないことを証明することもできます。
さらなる詳細について
より詳しい情報はこちらの論文をご覧ください。
謝辞
本ブログ記事へのフィードバックと、ここで紹介させていただきました機能実装への貢献について、以下の共著者に感謝します: Gefei Tan, Tudor Ioan Cebere, Aurélien Bellet, Hamed Haddadi, Nicolas Papernot, Xiao Wang, Adrian Weller




