Bring Your Own Model (BYOM): Brave Leoで自分のLLMを使う
注釈: 2024/8/22、現在BYOMは安定版のBraveに搭載されており、バージョン1.69以降の全てのデスクトップユーザーがご使用いただけます。
AIアシスタントはモダンなWebブラウザの一部となりつつあります。BraveにはLeoが、EdgeにはCopilotが、OperaにはAriaが、ArcにはMaxが… このAI統合の新たな波は、開発者やユーザーの間で多くの疑問を生み出しています。ブラウザでAIアシスタントと対話する最適な方法は何か?AIがブラウザに導入されることで、どのようなユニークな体験が生まれるのか?そして、おそらくこれが最も重要なことでしょう。 ユーザーのデータを効果的に保護し、ユーザーが独自のAIモデルを設定できるようにするにはどうすればいいのか?
BraveがLeoについてどのように考えているか、そしてブラウザ内のAI統合(別名ブラウザAI)の将来を綴ったLeoロードマップで、私たちはユーザーがローカルでモデルを実行し、独自のモデルを設定できるようにする必要性を述べました。ローカルで(デバイス上で直接)モデルを実行することで、AIアシスタントとやり取りされる会話、Webページ、文章作成プロンプトなどのデータがユーザーのデバイスで完結します。このアプローチはまた、エンドユーザーのプライバシーを守りながら、ローカルデータでユーザーを支援する機会を新たにつくることになります。さらに、ローカルで実行されるかリモートでホストされるかにかかわらず、ユーザーが独自のAIモデルを設定できるようにすることで、BraveはユーザーがAIの動作、出力、能力を特定のニーズや好みに合わせてカスタマイズできるようにします。
あなたのモデル、あなたのルール
その約束に向けた私たちの第一歩は、「Bring Your Own Model」(略して「BYOM」)です。BYOMは、Braveのネイティブ・ブラウザーAIであるLeoを使用するための新しい方法で、ユーザーが自分のAIモデルを直接使用できるようになります。BYOMは、ユーザーが自分の端末上で安全かつプライベートにローカルモデルをLeoで実行できるようにします。ユーザーは、自分のコンテンツがデバイスから外部に出力されることなく、Webページ(およびドキュメントやPDF)についてLeoにチャットしたり質問したりできるようになります。
BYOMは、ローカルモデルだけに限定されません。BYOMユーザーは、Leoを自社サーバーや(ChatGPTなどの)サードパーティが運営するリモート・モデルに柔軟に接続することもできます。これにより、ユーザーや組織は、独自のモデルやカスタムモデルを使いながらも、ブラウザー内で直接AIにクエリーできる利便性を享受できるようになり、新たな可能性が広がります。
BYOM では、リクエストはユーザーのデバイスから指定されたモデルのエンドポイントに直接行われ、Braveを完全にバイパス(素通り)します。Braveはユーザーとモデル間のトラフィックにはまったくアクセスできません。この直接接続により、ユーザーのエンドツーエンドの制御が保証されます。
BYOMは現在、開発者とテスター向けにBrave Nightlyチャンネルで提供されており、今夏の後半にフルリリースされる予定です。また、BYOMは当初はデスクトップ・ユーザーが対象となります。
BYOMでローカルモデルをLeoで使用する
BYOMを試すのに特別な技術的知識やハードウェアは必要ありません。ローカルLLMの状況は急速に進化しており、今ではわずか数ステップで高性能なローカルモデルをオンデバイスで実行することが可能です。
例えば、趣味でローカルLLMを実行するためのフレームワークとして、Ollamaを例にします。Ollamaフレームワークは、829MBから40GBまでの幅広いローカルモデルをサポートしています。
簡単な二つのステップでローカルLLMをBrave Leoで使用することが可能です。
ステップ1: Ollamaのダウンロードとインストール
まず https://ollama.com/download でOllamaをダウンロードします。お使いのプラットフォームを選択し、ダウンロードしてください。ローカル・モデルを使用したい場合は、毎回サービング・フレームワークを起動する必要がありますので、ファイルをダウンロードし解凍したら、アプリケーションをコンピュータのデスクトップやアプリケーションフォルダなど、アクセスしやすい場所に移動してください。
次に、アプリケーションをクリックして開くのを待ち、インストール手順を完了させてください。

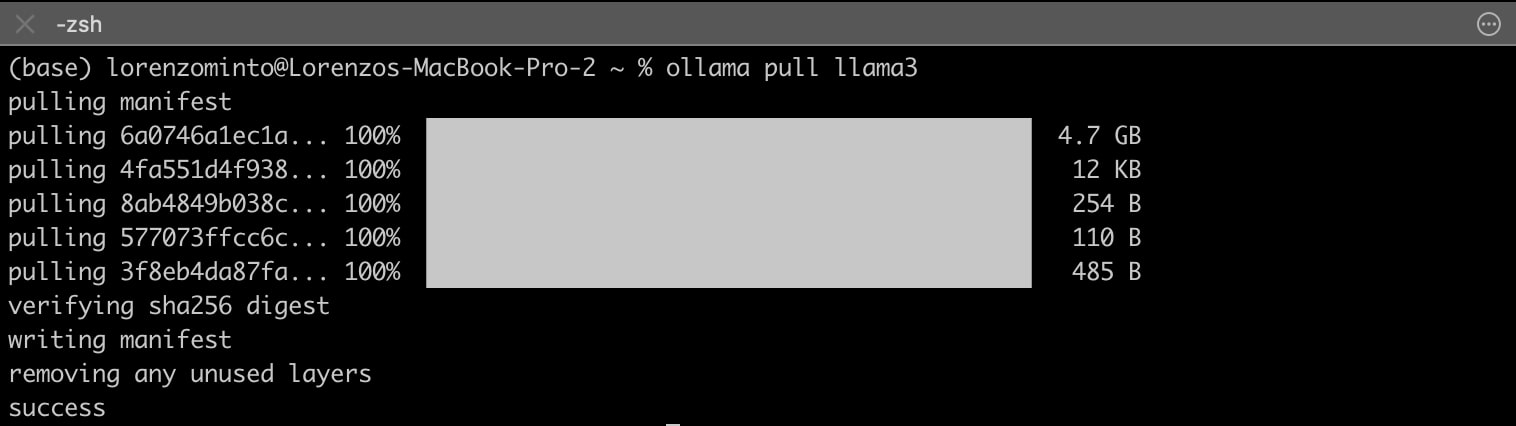
これらのステップを完了しFinishをクリックすると、ターミナルを開いて以下のコマンドをタイプするだけで、あなたのマシンでMetaのLlama 3モデルを実行できるようになります。
ollama pull llama3モデルマニフェストとモデルがダウンロードされていることが確認できるはずです(ファイルサイズと接続速度によって、このステップが完了するまでに時間がかかる場合があります)。モデルが正常に取り込まれたら、ターミナルを閉じます。
Llama 3は、8Bパラメータモデルで4.7GBと、品質と性能のバランスが取れており、少なくとも8GBのRAMを搭載したノートパソコンで簡単に実行できます。その他、Mistral 7B(Mistral AI社製)、Phi 3 Mini(マイクロソフト社製)などがローカルでの実行に適していることが確認できています。Ollamaがサポートするモデルの全リストはこちらをご覧ください。
このとき、モデルは端末上でローカルに動作しています。データは3rdパーティに送信されません。あなたのデータはあなただけにとどまります。
ステップ2: Leoへのプラグイン
自分のローカルモデルをLeoに追加するには、Braveブラウザを開き、 設定 → Leo の順にアクセスします。 Bring your own model セクションまでスクロールし、 Add new model をクリックします。
モデルの詳細を入力するインターフェイスが表示されます。それぞれの項目は以下の通りです。
-
Label: モデルセクションメニューで表示されるモデルの名前
-
Model request name: フレームワークへのリクエストで表示されるモデル名 (例) llama-3 (フレームワークで想定されている名前を正しく設定しない場合、正しく動作しませんのでご注意ください。)
-
Server endpoint: フレームワークがリクエスト用にリスニングしているURL。詳細はフレームワークのドキュメントをご確認ください。(Ollamaの場合は常に
http://localhost:11434/v1/chat/completions) -
API Key: サードパーティ・フレームワークを使用する際に必要となる、APIキーやアクセストークンなどの認証情報。リクエストヘッダに追加されます。
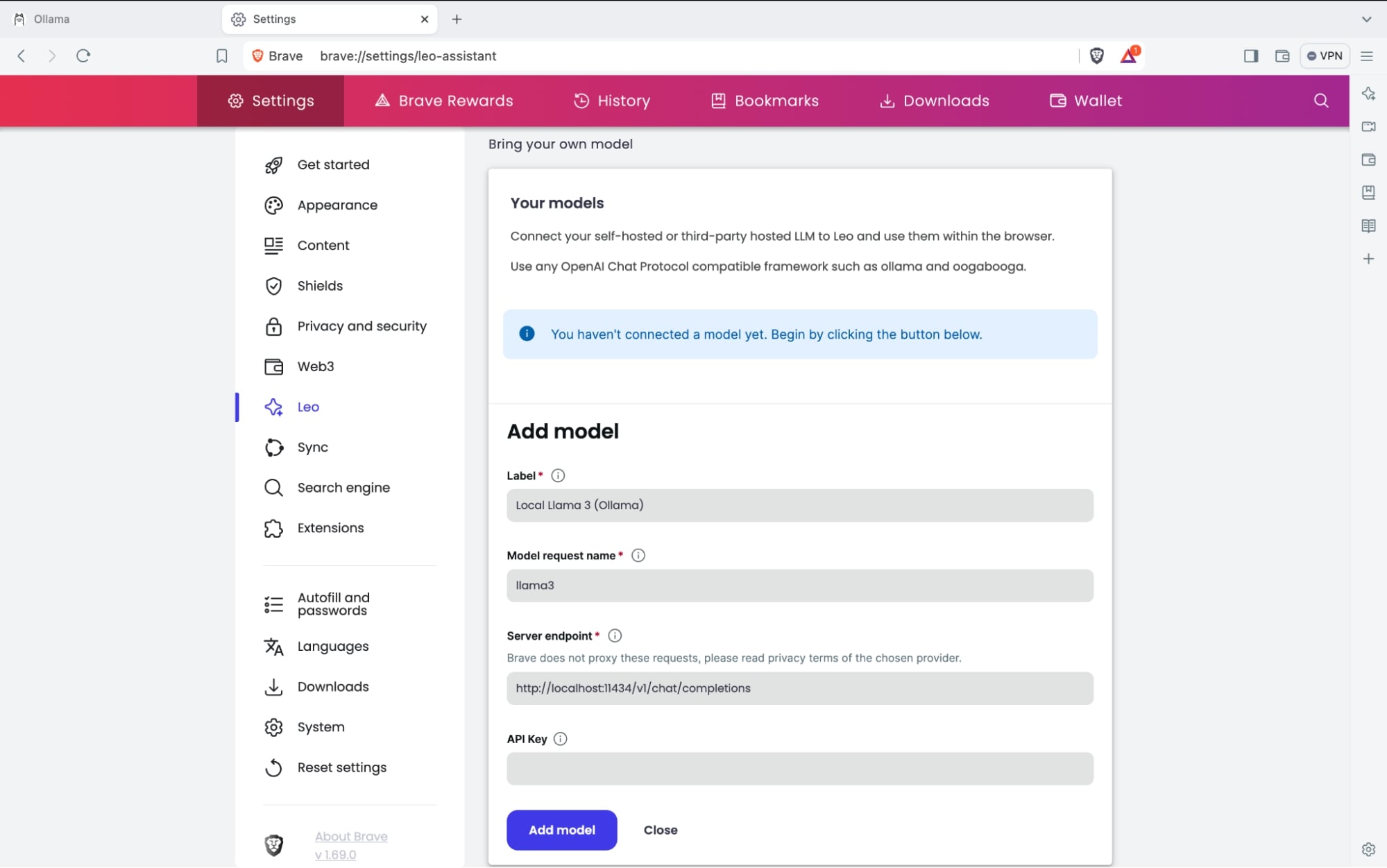
設定が完了したら Add model を押下してください。設定したローカルモデルがLeoのモデルメニューに表示されます。ここから選択することで、ブラウザAIとしてローカルモデルを活用することができます。
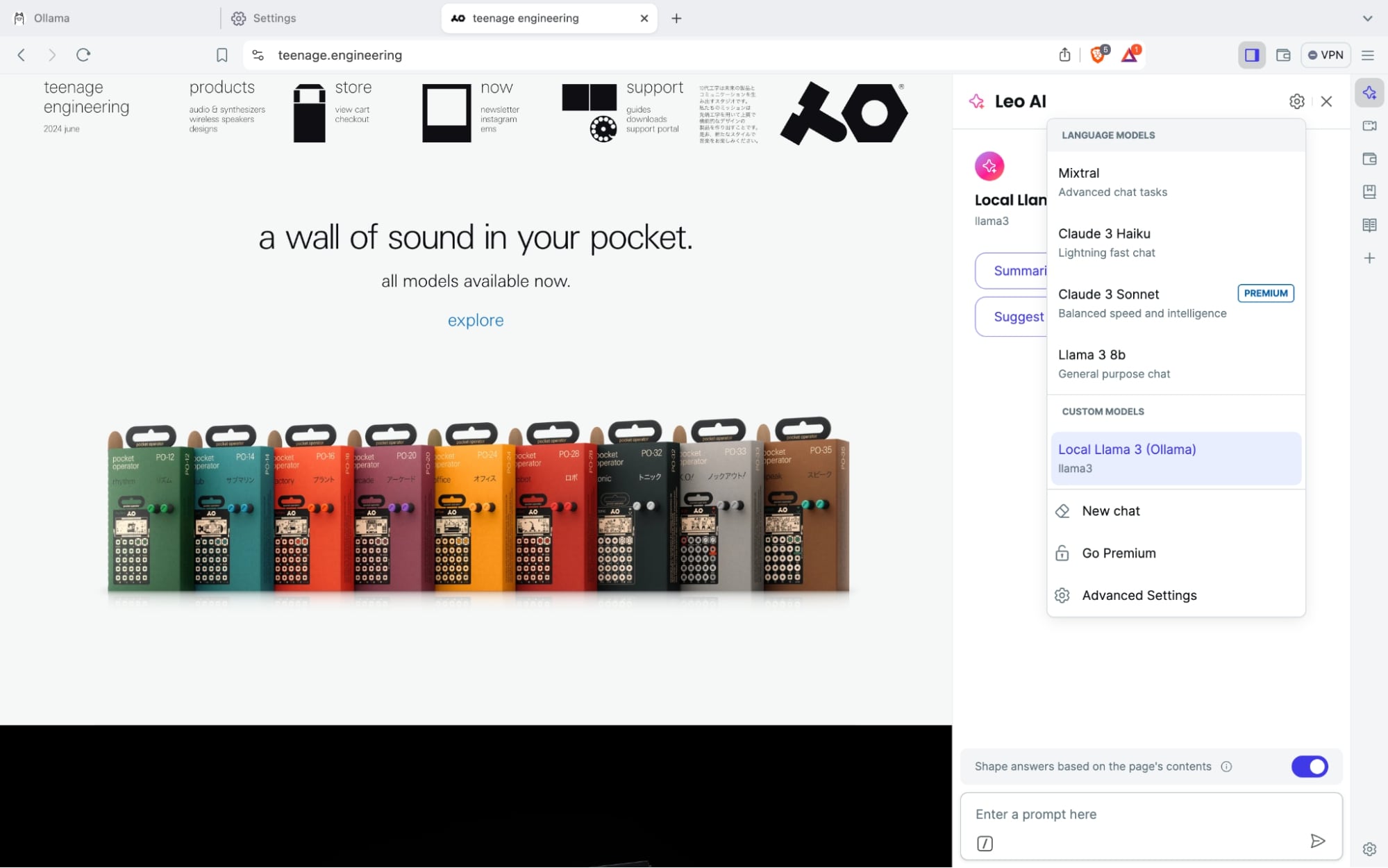
このセクションでは、Ollamaを使用しています。Ollamaは、OpenAIチャットプロトコルに準拠しており、ローカルモデルをセットアップして実行するための最も使いやすいフレームワークの1つだと考えているからです。しかしBYOMはエンドポイントが開放されているフレームワークを備えたローカルモデルはどのようなものでも設定することができます。
BYOMによりLeoでリモートモデル(ChatGPT)を使用する
以下はOpenAI APIを例にした、サードパーティAPIやリモートモデルにLeoを接続する手順です。
-
Model request nameにエンドポイントとしてhttps://api.openai.com/v1/chat/completionsを設定し、使用したいモデルの名前(例:gpt-4o詳細はモデルリストをご覧ください)を入力してください。 -
APIへのリクエストで使用するプライベートAPIキーを入力してください。キーは安全にブラウザで保管されます。
なお、本稿執筆時点では、Brave Leoはテキスト入力と出力にのみ対応しています。テキスト以外の形式は処理されません。また、ChatGPTでBrave Leoを使用するには、ご自身のOpenAI APIアカウントを通じた形でのみ使用可能です。
もしBrave Nightlyを使用されていましたら、ぜひBYOMをお試しください。そして感想をX @BraveNightlyや https://community.brave.app/ でお知らせください!




